ناقشنا في الدرس السابق
perceptron
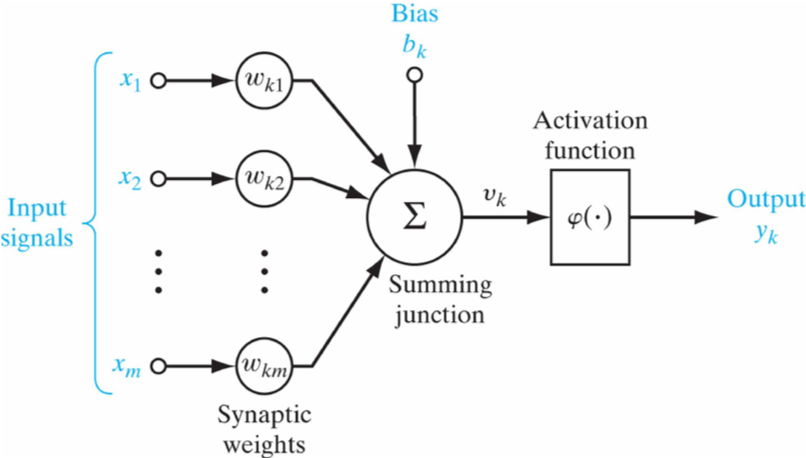
بالتفصيل وعرفنا انه يحتوي خلية عصبية واحدة فقط كما في الصورة رقم ١ ادناه.
في حال كانت الصورة غير مفهومة لك او الموضوع جديد عليك اضغط هنا لمشاهدة المقالة المتعلقة بالموضوع.
perceptron صورة رقم ١ : الهيكل العام ل
اذا نتذكر كيف نتعامل مع
perceptron
كنا نجيب dot product عن طريق ضرب x وهي المدخلات في w
وهي الاوزان التي نهئيها في البداية بشكل عشوائي ومن ثم في كل مرة نحدث قيم الاوزان عن طريق المعادلة التالية:
weight = weight + Learning Rate (expected – predicted) * x
الى ان نصل الى قيم الاوزان التي تقلل لنا نسبة الخطأ بين قيمة label الحقيقة الموجودة في البيانات وبين قيمة label المتوقعة من قبل المودل model. في هذه المقالة سنتحدث عن
Multilayer perceptron MLP.
طيب أول سؤال ممكن يجي في ذهنك ما الفرق بين Multilayer perceptron MLP وبين
perceptron؟
الفرق بسيط جدا وهو ان
Multilayer perceptron
يحتوي على اكثر من طبقة layer وكل طبقة تحتوي ايضا على اكثر من وحدة عصبية والسبب انه نريد نعالج مشاكل اكثر تعقيد والتي نحتاج لها اكثر من خلية عصبية في كل
layer. تعال نرى الشكل العام ل
Multilayer perceptron
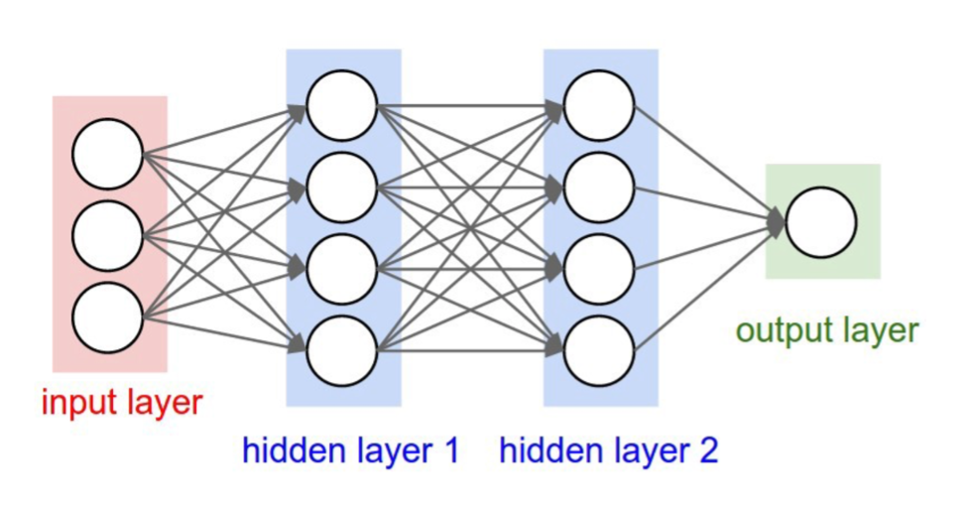
كما في الصورة رقم ٢ ادناه
Multilayer perceptron صورة رقم ٢ : الهيكل العام
طيب نلاحظ انه عندي اكثر من طبقة وفي كل طبقة عندي اكثر من وحدة عصبية.
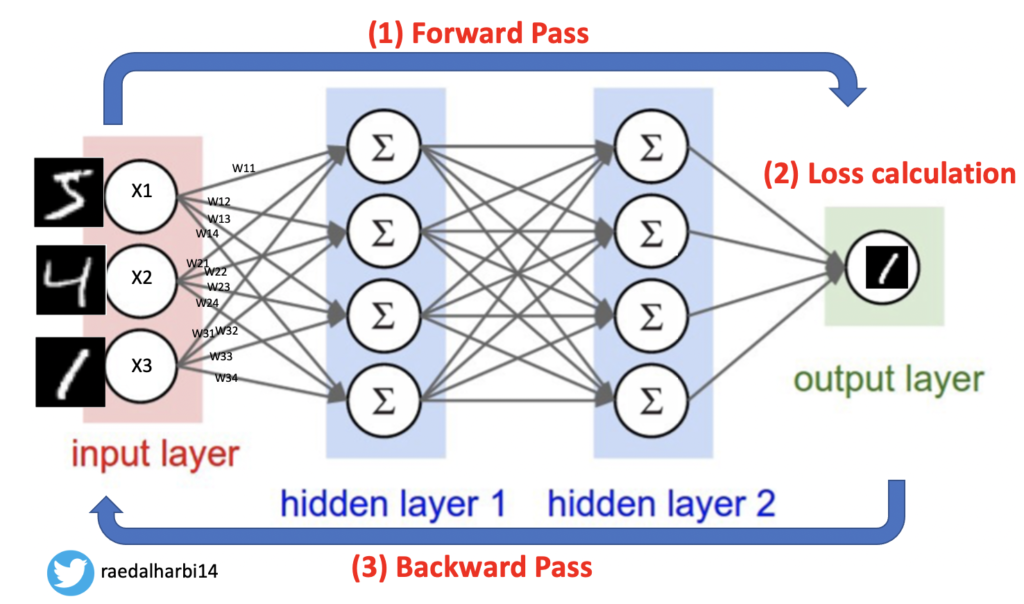
طيب تعال خلينا نشوف بالتفصيل ماذا تحتوي هذه الشبكة مثل ما نشوف في الصورة ادناه رقم ٣.
Multilayer perceptron صورة رقم ٣: مثال تفصيلي ل
تعال نحلل الصورة رقم ٣ بالتفصيل عن طريق مثال. افرض انه نبغى نبني نموذج model يتعلم ويصنف الارقام . يعني نعطي المودل صورة فيها رقم والمودل يتوقع لي الرقم الموجود في الصورة. تمام؟
الان افرض انه نمتلك البيانات الكافية لتدريب الmodel. والبيانات تحتوي على صور ارقام مختلفة من ٠ الى ٩ وايضا كل رقم مقابله ال label الخاص فيه. يعني صورة رقم ٦ تاخذ label رقم ٦ وهكذا.
لماذا الصور تكون مربوطة ب label خاصة فيها؟ ممكن تقول الصور خلاص مكتوب عليها الرقم صح؟
الكلام صحيح بالنسبة لنا. لكن تذكر احنا نتعامل مع الة فالمودل model ما حيعرف انه الصورة رقم ٦ من وحده. والحل؟ الحل انه خلاص فترة التدريب training phase نعطي المودل model صور الارقام وال labels وبعد ذلك المودل model يتعلم منها. كيف؟
مثلا اعطينا المودل model صورة رقم ٦ فالمودل حيستخرج الخصائص ويشوف هذه الخصائص تنتمي لاي label؟ وفي مثالنا اذا رأى الخصائص التي تدل على انه الرقم في الصورة هو رقم ٦ فيحعرف انها ل label ٦ لان احنا ذكرنا واعطينا له هالمعلومة انه الصورة هاذي رقم ٦ تراها ل label ٦ ووظيفتك ان تتعلم ماذا يميز الصورة من خصائص وتقرنها بlabel. لماذا؟ حتى اذا جاء وقت اختبار المودل testing phase حنعطي المودل فقط الصور وهو يتوقع لي labels. بالتالي، المودل حيتعامل معاها مثل ما تدرب حيبدا ويستخرج الخصائص ومن ثم يشوف هالخصائص هيا اقرب لاي label بناء على الذي رأه في فترة التدريب ومن ثم يقوم باعطاء التوقع وهو label الاقرب للرقم في الصورة.
طيب احنا الحين فهمنا المطلوب. جاء وقت انه نبني او نصمم نموذج Multilayer perceptron model يقوم بتصنيف الارقام.
دائما حتى تسهل على نفسك فهم اي شبكة، اسال نفسك الاسئلة التالية :
ما هي مدخلات الشبكة inputs ؟
ما هي مخرجات الشبكة output؟
في مثالنا هذا المدخلات inputs حتكون مجموعة من الصور وتحتوي على ارقام مختلفة من ٠ الى ٩ زي ما نشوف في الصورة رقم ٣.
والمخرج النهائي output حيكون انه يصنف لي الرقم الي تحتويه الصورة.
نجي الان نشوف كيف ندرب الشبكة العصبية. طبعا
في أي شبكة عصبية سوا
Multilayer perceptron
او
CNN
او غيره تتكون من ثلاث خطوات رئيسية:
Forward pass
Calculate error or loss
Backward pass
خلينا نتكلم عن كل خطوة بالتفصيل. أول شي افرض انه عندنا البيانات متوفرة وهيا عبارة عن مجموعة من الصور وكل صورة رقم مرتبطة ب
label
خاص فيها من أجل الشبكة تعرف انه الخصائص المعينة ل
label
المعين. وخلال مرحلة التدريب احنا حنمرر المدخلات مع labels
الخاصة فيها من أجل شبكتنا تتعلم.
Forward pass:
ما الهدف من هذه المرحلة؟ الهدف انه احنا نضرب قيم المدخلات X وهي الصور بقيم الاوزان w التي نريد ان نتعلم قيمها لان نريد قيم الاوزان weights w اقرب ما تكون لقيم الخصائص في الصور حتى لو اعطينا المودل صور جديدة حيضرب قيم الصورة الجديد ب w التي اتعلمها في مرحلة التدريب وبالتالي يصنف او يتوقع ال label للصورة بشكل صحيح.
طبعا في البداية قيم w حتكون مهئية بقيم عشوائية. بالتالي اذا ضربنا او بما معناه نفذنا forward بين جميع x و w لجميع الطبقات حتى نوصل للنهاية مثل ما نشوف في الصورة رقم ٣.
يعني بالمختصر نمشي من اليسار الى اليمين جهة المخرجات.
ماذا يعني هالكلام بالتفصيل؟
المعنى انه نربط بين طبقة المدخلات input layer مع الطبقة المخفية الاولى hidden layer ومن ثم الطبقة التي بعدها حتى نصل للمخرجات.
أكيد بتسال كيف طريقة الربط؟
مثل ما ذكرت قبل وهو انه نضرب فقط والضرب اعني فيه dot product واتكلمت عنها في مقالة سابقة وهي باختصار يعني اضرب جميع قيم x في w حتى نصل النهاية. وبعد ذلك نحسب activation function.
تعال ناخذ مثال من الصورة رقم ٣. لو نظرنا الى الوحدة العصبية الاولى في الطبقة الاولى، حتكون نتيجة الحسبة كالاتي:
activation function
(x1w11+x2w21+x3w31) ok
يعني ناتج الوحدة العصبية حيكون انه نحسب
dot product لجميع المدخلات
ونطبق نفس الكلام على الوحدات العصبية المختلفة في الطبقات المختلفة.
طيب يكون بعدين وصلنا للمخرجات صحيح؟ وربطنا بين الطبقات المختلفة. وبعدين؟ هنا يجي دور الخطوة الثانية.
Calculate error or loss:
طيب احنا للحين وصلنا للمخرجات يعني نتيجة الضرب تعطينا ال label المتوقع من قبل المودل. لا تنسى في البداية قيم w عشوائية بالتالي نتيجة التوقع حتكون خطأ. لنفرض
انه مررنا للشبكة الصورة رقم ٥
مع label
الخاص فيها وهو ٥.
والشبكة توقعت لي الصورة رقم ٥ انها تنتمي للكلاس رقم ٧ او بمعنى اخر توقعت
label الخطأ وهو رقم ٧.
توقعت لنا الرقم بشكل خاطئ ما السبب؟ لان مثل ما ذكرنا قيم
w
في البداية هيئناها بقيم عشوائية. فالشبكة الى الان ما اتعلمت.
نتأكد كيف؟ نحسب نسبة الخطا باستخدام loss function او احيان تسمى loss error وهي نسبة او فرق الخطأ بين label الحقيقي الموجود في البيانات وبين label الذي توقعه المودل الخاص فينا وهو ناتج dot product او element wise multiplication. اذا كان فرق نسبة الخطأ كبير فاحنا نحتاج نقلل هذه النسبة. كيف نقللها؟ عن طريق تحديث قيم الاوزان بقيم افضل. كيف يتم هذا؟ عن طريق الخطوة الثالثة.
Backward pass:
طيب اعرفنا انه قيمة
w
عندنا خطا فنبغى نحدثها. فالطريقة نحدثها باستخدام المعادلة التالية الخاصة
Gradient Decent كالاتي:
ماذا يعني هالكلام؟ يعني انه احنا نرجع للوراء مثل ما نشوف في الصورة رقم ٣. وهذه العملية تسمى backpropagation. يعني احنا نبدا نحدث كل الاوزان في كل طبقة عن طريق gradient decent الذي يتم العملية عن طريق الاشتقاق. حيث يحاول ال gradient decent يوجد قيمة الاوزان التي تقلل نسبة الخطأ.
ان اصبت فمن الله وان اخطات فمن نفسي ..
لا تنسى مشاركة المقالة اذا أعجبتك ..
اخوكم رائد الحربي
ولاي ملاحضات او استفسارات يرجى مراسلتي على تويتر @raedalharbi14 أو كتابة التعليق هنا