في المقالة هذه ان شاء الله حجيب على الاسئلة التالية بخصوص gradient decent.
ماهو gradient decent? لماذا نستخدمه هو بالذات عن أي خوارزمية اخرى؟
لماذا نستخدمه في أغلب نماذج تعلم الآلة أو التعلم العميق؟ كيف يستخدم ومتى؟ هل واجهتك صعوبة في ربط فكرته النظرية مع النماذج العملية الموجودة؟
أول شي اعرف هدف gradient decent انه يحدد لنا قيمة الوزن weights التي تقلل نسبة في الخطأ في اي دالة. حفصل ونفهم مع بعض ماذا اعني بهذا الكلام.
فكر ب gradient decent كواحد جالس فوق جبل وانه gradient decent هو الي يساعدك توصل لقاع الجبل. ممكن توضح رياضيا أكثر؟ رياضيا يعني انه باستخدام gradient decent نحن نحاول نوجد أقل قيمة في دالة معينه لان هيا التي تقلل لي نسبة الخطأ. على العكس لو احنا مهتمين انه نجيب اعلى قيمة في دالة حنستخدم gradient ascent او تخيل انه احنا جالس نصعد للجبل.
السؤال المهم لماذا احنا مهتمين انه نجيب أقل قيمة local minimum لدالة معينة؟
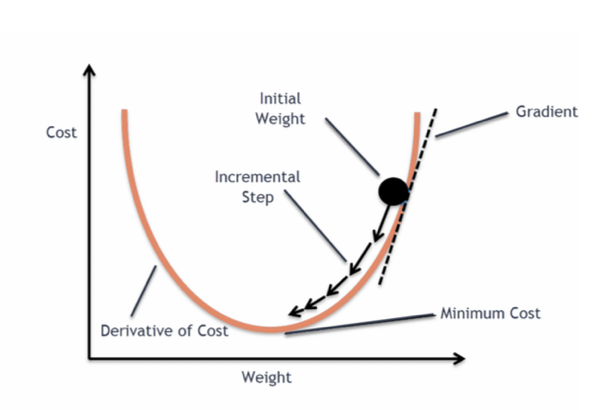
Gradient Decent : رقم الصورة ١
تعال نفهم الصورة رقم ١ ونحللها. اعتبر اللون البرتقالي هو الدالة التي نجيب أقل قيمة لها او اعتبر اللون البرتقالي هو الجبل الذي نحاول أن نوصل لقاعه. تمام؟ الان ال gradient في الصورة رقم ١ هو الخط المنقط او ما يعرف رياضيا بالميل slope.
طيب نحن نحاول نوجه gradient حتى ينزل للقاع ونحسب أقل قيمة للدالة. وهذا يتم عن طريق مساعدة الاشتقاق derivative. طيب النقطة السوداء الكبيرة اعتبرها الوزن weight الذي نحاول نوجد القيمة المناسبة له حتى نوصل للقاع. وهذا الوزن في البداية نعطيه قيم عشوائية وبعدين كل ما نبدا ننزل باستخدام الاشتقاق نقدر نحدد مقدار كمية النزول عن طريق step. يعني هل بسرعة بتنزل أو لا؟ بس انتبه لو نزل بسرعة زائدة ممكن تعدي القاع وتروح الجهة الثانية.
حسابه سهل جدا باستخدام دوال جاهزة وحنشوف كيف اذا تطرقت للجانب العملي فما حندخل في الجانب الرياضي الذي لا نحتاجه وحنركز على النقاط المهمة التي نحتاجها. طيب باختصار ال gradient decent يحدد لنا قيمة الوزن weights في weghit vecotr واعني انه تخيل معاي انه عندي صندوق وفيه اوزان كثيرة ومسؤولية gradient decent انه يحدد لي القيم المناسبة التي توصلنا الى اقل القيم او القاع وبالتالي نقلل نسبة الخطا في الدالة.
ما علاقة هذا كله بالتعلم العميق ؟! وكيف أربط هالكلام بنماذج models الخاصة بالتعلم العميق؟
الدالة التي كنت اتكلم عنها تمثل ال cost function. خلينا نشوف ما هيا ال cost function وبعدها نربط كل الامور مع بعض.
Cost Function دالة الخطأ
في أي خوارزمية او نموذج model في التعلم العميق هدفنا الأساسي الذي نسعى له هو تقليل نسبة الخطأ بين التوقع للمودل الخاص فينا predctions وبين الناتج الاساسي او القيمة الأساسية. ما فهمت؟ حوضحها بشكل اافضل بالمثال.
Linear Regression
يوجد عندنا أنواع مختلفة في التعلم العميق احدها هو linear regression وتكلمت
عنه بالتفصيل في
هنا
والتطبيق العملي له في هذا الدرس للمهتمين.
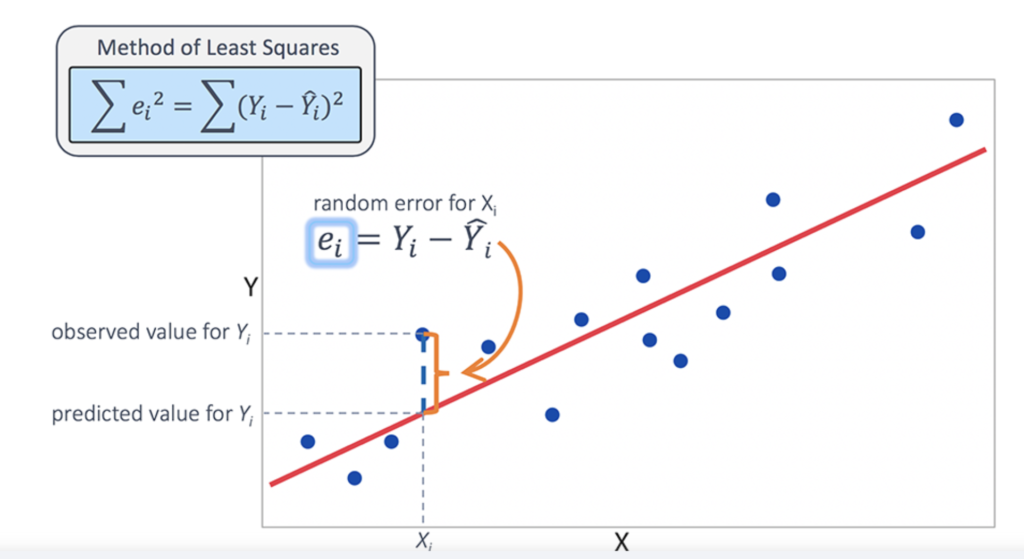
Linear Regression Model صورة رقم ٢ : حساب عينة واحد من
هدفنا من بناء أي نموذج model هو أن نريد أن نتعلم.
اذا أردنا أن نبني مودل model خاص بال linear regression فهدفنا ان الخط الاحمر في الصورة رقم ٢ يكون في المنتصف بين البيانات. ممكن تفصل أكثر؟ معنى هالكلام انه الخط الاحمر يمثل المودل modelالخاص فينا.
لماذا المودل model وهو الخط يجب ان يكون في المنتصف بين البيانات في صورة رقم ٢؟ حتى نقول انه المودل الخاص فينا اداء بشكل ممتاز؟
شوف معاي صورة رقم ٢ وخلينا نفهمها وحدة وحدة. اعتبر ال y الموجودة على y-axis هيا اسعار الاراضي في مدينتك. تمام؟ واعتبر ال x هيا احجام الاراضي. بالتالي اذا حجم الارض كبير حيكون سعرها عالي وهكذا. الان نسال انفسنا ايش هدفنا من بناء النموذج model؟ ماهي البيانات المتوفرة عندنا؟
هدفنا نبني مودل model يتعلم ويتوقع لي سعر الارض بناء على خاصية feature والخاصية في مثالنا هذا هيا حجم الارض. فبتالي نبغى نبني مودل model يتوقع سعر الارض بناء على حجم الارض. تمام للان؟
طيب كيف يتعلم بالتفصيل؟ هذا اتكلمت عنه بالتفصيل في رابط الدروس فوق لكن ما يهمنا الحين نعرفه كيف طريقة التعلم بشكل عام.
طيب نفرض انه عندنا البيانات لاحجام الاراضي وفي المقابل اسعارها. في فترة التدريب للمودل training phase احنا حنعطي المودل هالمعلومات ونقوله ترا اذا شفت الارض حجمها كبير ترا سعرها كبير وهكذا مثل ما نشوف في الصورة رقم ٢ في النقاط الزرقاء. طيب الحين نجي لفترة اختبار المودل testing phase for our model. احنا في هالفترة نعطي المودل فقط حجم الارض وهو يتوقع لي سعرها.
طيب احنا نبغى المودل يتدرب بشكل ممتاز بحيث يحاكي فعليا اسعار الاراضي بناء على حجمها. ولنفرض انه دربناه بشكل ممتاز وهذا يعني الخط الاحمر في منتصف البيانات. يعني حاولنا نحاكي بيانات التدريب وهيا النقاط الزرقاء على قد ما نستطيع. تمام؟
قلت لك قبل شوي في فترة الاختبار testing phase احنا نعطي المودل حجم الارض وهو يتوقع سعرها. طيب تعال نسوي هالشي بالضبط في الصورة رقم ٢. شوف xi وهاذي تمثل عينة لحجم ارض. الان مسؤولية المودل ان يتوقع سعرها.
المودل model حيروح ويشوف xi فين مكانها على الخط الاحمر واحنا ذكرنا انه الخط هو المودل الخاص فينا. بعد ذلك السعر المقابل لها هو التوقع وهنا يمثل yi الموجودة والتي تكون على الخط.
الان جاء دور دالة الخطأ cost function ودالة الخطأ في مثالنا هذا لعينة واحدة هيا حساب الفرق بين سعر الارض الحقيقي والسعر المتوقع من قبل المودل الخاص فينا. كما نشوف في الصورة رقم ٢ . فاحنا نوجد نسبة الخطأ بين القيمة الحقيقة والقيمة المتوقعة من قبل المودل.
واحدى الدوال المشهورة هيا
Least Square Error والعلامة التي مثل حرف E هيا لكل العينات.
وبالتالي المعادلة تعني لكل العينات كل مرة جيب لي فرق الخطأ (بين الشي المتوقع والشي الحقيقي) ومن ثم جبنا التربيع power to 2. طيب التربيع باختصار لان لا نريد قيم سالبة لان المسافات عندنا لا تكون بالسالب فعشان نتخلص من السالب ربعنا.
طيب ما علاقة كل هذا ب Gradient Decent?
انظر للخط الاحمر. الخط الاحمر هذا يمثل المعادلة الخطية التالية:
y = w*x + b
الاكس هنا اعتبرها الخصائص واعتبر عندنا خاصية حجم الارض وهيا قيمة معلومة. يعني احنا نبغئ نجيب قيمة w and b الي تخلي التوقع للمودل الخاص فينا yi اقرب ما تكون لyj الحقيقية. يعني توقع سعر الارض وخليه يكون قريب من السعر الحقيقي لارض مشابهة في الحجم في فترة ماضية وهيا التي رأها المودل في فترة التدريب.
لان اذا جينا ندرب اي نموذج عندنا البيانات فيه خصائص x وفي المقابل لها labels (y) يعني الكفر للسيارة مثلا فيه خصائص تدل أن السيارة تايوتا.
فالكفر هنا x وال y هيا سيارة التايوتا.
طيب الان كيف نجيب قيمة w and b؟
عندي خيارين: الأول انه نجلس نجرب ارقام من عندنا الى ما لانهاية ويمكن نوصل للحل ويمكن لا.
الطريقة الثانية انه اجيب الاشتقاق للدالة عشان اوصل للقاع !
فالحل هو Gradient Decent لان احنا في البداية عادة في التطبيق العملي نعطيه قيم عشوائية فاكيد في البداية نسبة الخطا عندنا حتكون عالية فعشان نقلل نسبة الخطا احنا نستخدم Gradient Decent حتى نحدث قيمة w and b حتى نوصل لاقل قيمة وهيا قاع الجبل والقيمة الموجودة في القاع هيا اقل نسبة خطأ
فالطريقة عمليا حتى نحسب ونسوي كل هذا هيا كالاتي:
اول شي نعطي w and b قيم عشوائية ونحسب قيمة الخطا.
بعدين نجلس كل مرة نحدث قيمة w and b بالمعادلة الاتية:
Wi = Wi – learning_rate * derivative (Loss function w.r.t Wi)
يعني قيمة w الجديدة تساوي قيمة w القديمة ناقص learning rate ومن ثم نضربه بالاشتقاق للدالة الخطأ بالنسبة لكل متغير. والمتغير هيا الاوزان weights الخاصة بالمودل.
علامة الناقص في المعادلة هيا التي تسمح لنا بالنزول الى القاع حتى نوجد قيمة الاوزان weights التي تقلل لنا نسبة الخطا. لو وضعنا موجب ماذا حيكون الناتج؟ حنصعد للجبل وهذا معناه حنجيب gradient acent. اما بخصوص ما هو learning rate فحشرحه بالتفصيل في المقالة بعد القادمة.
لو جينا نبسط معادلة تحديث الاوزان حيكون الناتج النهائي كالاتي:
حيث yi and yi hat هيا الفرق بين label المتوقع من قبل المودل والlabel الحقيقي الموجود في البيانات. x هيا المدخلات الخاصة فينا.
ملاحظة اخيرة:
يوجد نوعين مشهورة من Gradient Decent
هما Batch gradient descent and Stochastic gradient descent.
الفرق بينهما ان Batch gradient descent نستخدمه عندما نحدث ال w)weight) بناء على استخدام كل البيانات في dataset. وفي الجهة المقابلة Stochastic gradient descent يستخدم عندما نحدث w)weight) بعد كل مرة. يعني بعد كل عينة نبدا نسختدمه وهكذا.
ان اصبت فمن الله وان اخطات فمن نفسي ..
لا تنسى مشاركة المقالة اذا أعجبتك ..
اخوكم رائد الحربي
ولاي ملاحضات او استفسارات يرجى مراسلتي على تويتر @raedalharbi14 أو كتابة التعليق هنا