بعد ما رأينا في المقالات السابقة مكونات شبكة CNN. في هذه المقالة سنرى ما فهمناه نظريا لكن بشكل تطبيقي وعملي.
وابغى أوضح نقطة مهمة: هدفي من المشروع ليس بناء مودل قوي. لكن هدفي تطبق ما تعلمته في المقالات السابقة بحيث تفهم كيف كل شي ماشي وكيف الطريقة الصحيحة لبناء شبكتك العصبية وكيف تفهم مدخلات ومخرجات شبكتك وكيف تدرب وتختبر المودل بطريقة صحيحة. بالتالي، مهم تفهم كل خطوة والهدف منها وكيف استخدمتها حتى تستخدمها في مشروعك الخاص. فاذا تبغى تستفيد فعليا من المقالة هذه انصحك ترجع للمقالات النظرية أول لان حشير اليها كثير في هذه المقالة حتى تربط ما تعلمته في الجانب النظري بالجانب العملي في المقالة هذه. تعال نبدا
ماهو الهدف من المشروع؟
الهدف هو بناء بناء مودل model يقوم على تصنيف الارقام الموجودة في الصور من 0 الى 9 بناء على الخصائص المتوفرة في كل صورة رقم. يعني مثل رقم 0 يحتوى خطوط تدور حول بعضها البعض وهكذا. وكل رقم له خصائص مختلفة عن الارقام الاخرى.
ما هيا البيانات المستخدمة؟ وكيف نتعلم منها؟
البيانات التي حنستخدمها هيا من قاعدة بيانات معروفة وهيا MNIST. تحتوي MNIST على صور مختلفة للارقام المكتوبة بخط اليد. يعني مدخلات الشبكة حتكون الصور التي تحتوي على الارقام والمخرجات حتكون صور الارقام ولكن كل صورة مربوطة بالرقم الصحيحة. يعني الصورة رقم ٦ توقع المودل يجب ان يكون الصورة التي تحتوي رقم ٦
بناء على الخصائص التي تعلمها من خلال convolutional layer كما رأينا في المقالات السابقة كيف تتم عملية استخراج الخصائص.
تعال نرى كيف شكل البيانات:
الهيكيل العام للشبكة مع البيانات
الان طريقة بناء المودل model تتم على مرحلتين:
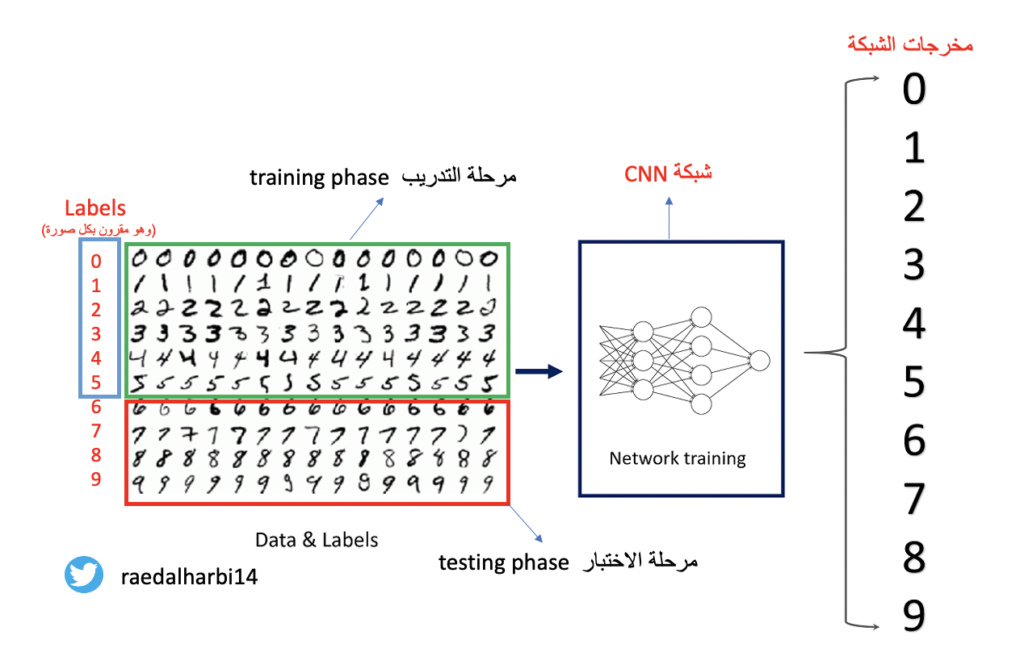
مرحلة التدريب training phase: في هذه المرحلة احنا نعطي المودل model الخصائص بالاضافة الى labels مثل ما نرى في الصورة رقم ١ حيث مرحلة التدريب تحتوي المربعين باللون الاخضر والارزق الفاتح. لكن لماذا مدخلات المودل تكون الخصائص بالاضافة الى labels؟ لماذا لا نكتفي بالخصائص فقط بما انه احنا نريد توقع الصورة الموجودة في الرقم فقط؟ السبب بسيط وهو انه احنا نتعامل مع ألة بالتالي في مرحلة التدريب احنا حنخبر المودل انه اذا شفت الخصائص التي تدل على انه الرقم الموجود في الصورة مثلا رقم ٦ فاذن اسند له ال label الخاص فيه والذي هو رقم ٦. ففكر في ال label كملصق مع الصورة.
مرحلة الاختبار testing phase: هنا خلاص المودل المفروض تدرب كفاية. فاحنا في هذه المرحلة نعطي المودل فقط الخصائص والتي هيا الخصائص المميزة لكل رقم ومن ثم الان دور المودل ان يقوم بتوقع ما اذا كان الرقم الموجود في الصور هو رقم مثلا ٥ او غيره والتوقع هو labels لان المفروض تعلم يفرق بين الخصائص التي تخص وتميز كل رقم عن الاخر في مرحلة التدريب. طبعا بيانات التدريب في MNIST عددها ٦٠٠٠٠ صورة.
ملاحضة: كيف نتأكد من توقعنا انه صحيح؟ حنرجع لل labels في البيانات ونتاكد هل هو فعلا توقع المودل او لا. لان labels موجودة عندنا من الاساس بس ما اعطيناها المودل لان وظيفته يتوقع لنا في مرحلة الاختبار. طبعا البيانات والتي هيا صور الارقام الخاصة بالاختبار عددها ١٠٠٠٠ صورة.
الان بعد المقدمة الطويلة ^ــ^ تعال نبدأ نشوف الأكواد
التعامل مع البيانات
تعال نفهم الكود خطوة خطوة. أول شي Pytorch موفرة لنا ميزة جميلة وهيا انه عنده مكتبة فيها قواعد بيانات مختلفة منها بيانات MNIST والتي حنشتغل عليها. في السطر رقم ١ احنا استعدينا المكتبة. وايضا استدعينا مكتبة اخرى لها استخدامات كثيرة وهيا transforms وحنشوفها ايضا في مقالات مختلفة. طيب السطر رقم ٣ احنا حملنا بيانات MNIST. في اول خانة في سطر رقم ٣ وهيا root وضعت المكان الي ابغى البيانات تتحمل فيه فتقدر تختار المكان الي يعجبك وتقدر تخليها مثل ما سويت انا هنا. والخانة الثانية في سطر رقم ٣ والتي هيا train = true وهنا تعني او نقول للمكتبة ترى احنا مهتمين فقط في البيانات الخاصة بالتدريب والتي هيا ٦٠٠٠٠ صورة ولهذا السبب سميتها train_dataset. طيب الخانة الثالثة في السطر ٣ استخدمت فيها transforms لاحول البيانات الى tensor لان مثل ما ذكرت سابقا حتى نتعامل مع pytorch لازم نحول البيانات الى tensor واخيرا قلنا له download = true حتي يحمل البيانات لان مو موجودة عندي.
نفس الكلام ينطبق على بيانات الاختبار والتي عددها ١٠٠٠٠ صورة لكن قلنا له هنا train = false معناته جيب لي البيانات الخاصة بالاختبار فقط. وكذلك حولنا هذه البيانات الى tensors.
ايش رأيك نتاكد من عدد البيانات؟ واحجام الصور؟
نشوف الكود التالي:
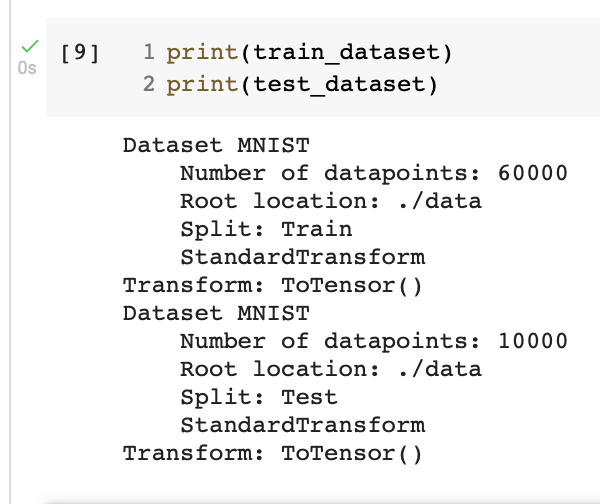
مثل ما نشوف طبعنا بيانات التدريب والاختبار ونلاحظ انه عدد بيانات التدريب ٦٠٠٠٠ صورة وعدد بيانات الاختبار ١٠٠٠٠ صورة. طيب هذا بالنسبة لعدد الصور لكن ما هو حجم كل صورة؟ واقصد فيه الطول والعرض لان حنحتاج نعرفهم حتى نعرف كيف نبني المودل ونقوله ايش الحجم الخاص بالصورة الذي حيستقبله. نشوف الكود التالي:
نلاحظ انه عندي ٦٠٠٠٠ صورة للتدريب وحجم كل واحد منها ٢٨ على ٢٨ اي طول وعرض كل صورة هو ٢٨. وايضا لاحظ انه ما عندي channel مثل ما ذكرنا وظيفتها مقالة convolutonal layer وبالتالي معناه اذا ما انكتب عدد channel ان عدد channel هو ١ وهيا الصور الرمادية. حلوين؟ اعرفنا الان اذا جينا نبني شبكتنا ايش الحجم المتوقع حسب بياناتنا. تعال نشوف صورة وحدة من ال ٦٠٠٠٠ في الكود التالي:
في السطر الاول استدعينا مكتبة matplotlib الخاصة بمعالجة وعرض الصور. نلاحظ انه في سطر ٢ طبعنا الصور وفي سطر ٣ طبعنا label الخاص بالصورة. وايضا حددنا اللون الرمادي لان مثل ما شفنا ما عندي channel. لكن السؤال الاهم
كيف نعالج هالكمية الكبيرة من البيانات؟ وامررها للشبكة التي حنبني مرة وحدة
ذكرت في مقالة سابقة ان نستخدم ال batch size لحل هذه المشكة بحيث كل مرة خلال مرحلة التدريب امرر مجموعة من الصور في حزمة ١ والتي تسمى batch وكل حزمة لها حجم والذي يحتوي على عدد الصورة التي تريد ان تكون في كل حزمة. فاكر هالكلام؟ لكن المشكلة:
كيف اقدر اقسم ال batches بشكل احترافي بحيث ما اخسر ذاكرة وانفذها بشكل سريع. ما هي افضل طريقة؟
هنا يجي دور dataloader التي وفرتها لنا Pytorch بحيث نقدر نقسم البيانات الخاصة فينا على شكل batches. وايضا وفرت لنا انه اقدر الف بمعني نعمل iteration على ال batches بطريقة سريعة جدا.
كيف نستخدم dataloader؟
نشوف الكود التالي:
نلاحظ انه انشائنا اثنين من dataloaders واحد للتدريب وواحد للاختبار وحددنا حجم الحزمة batch ب ١٠٠ . تبغى نشوف كيف نلف او نعمل iteration علي الloader؟ نشوف الكود التالي :
صورة رقم ١ : حجم البيانات الذي سيمرر للشبكة
الطريقة بسيطة اول شي نسوي iter لنفس dataloader والذي هو المتغير dataiter. وبعد ذلك في سطر ٢ في كل لفة iter نقول له جيب الي بعده ونستخرج لimages و labels لان next يرجع لي الصورة والlabel الخاص فيها. بعد ذلك في سطر ٤ طبعنا نتاكد ونشوف انه فعليا الان كل حزمة فيها ١٠٠ صورة وحجمها ٢٨ على ٢٨ وعدد م channel هو ١ مثل ما نشوف. يعني هذا هو الحجم الذي بناء عليه نبني المودل. وفي سطر ٥ طبعا حجم ال labels ونشوف انه ١٠٠ والتي هيا خاصة بالحزمة للصورة التي ذكرنا. بما انه عندي حجم الحزمة ١٠٠ وعدد الصور الخاصة ببيانات التدريب هيا ٦٠٠٠٠ صورة. بالتالي كم عدد الحزم batches عندنا؟ المفروض ٦٠٠ لان ٦٠٠٠٠ على ١٠٠ يعطيني ٦٠٠. نتاكد؟ نشوف الكود التالي:
فعلا طبع ٦٠٠ ونفس الكلام بالنسبة لبيانات الاختبار لكن حيعطينا ١٠٠ لان ١٠٠٠٠ على ١٠٠ تساوي ١٠٠.
بناء شبكة CNN
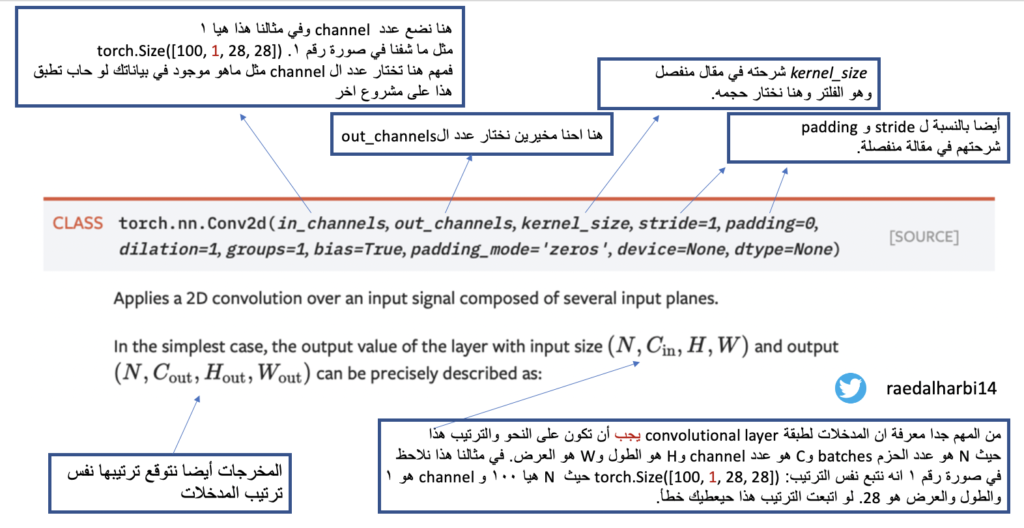
قبل نشوف المودل الذي سنبنيه، ابغى طبقة ال convolutional layer من المصدر الاساسي ونحاول نفهم ايش تبغى كمدخلات وكيف شكلها؟ نشوف الصورة التالية:
convolutional layer صورة رقم ٢ : مدخلات ومخرجات طبقة
وضحت في الصورة اعلاه ال parameters المهمة التي تحتاجها عند استخدام الconvolutional layer في اي مشروع مو فقط على مشروعنا هذا. وايضا وضحت ماهيا المدخلات التي يجب ان تكون وما المخرجات للطبقة. لكن السؤال كيف نحسب ما هو مخرج الشبكة؟ حتى اعطي العدد للطبقة التي تليها؟ نشوف المودل في الكود التالي:
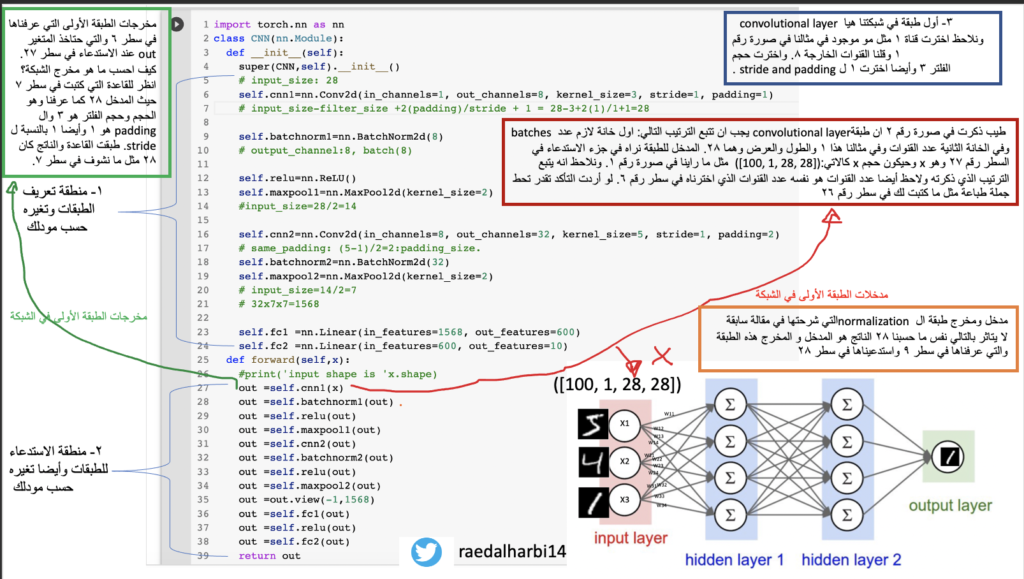
CNN صورة رقم ٣: مودل
المربع الاحمر في الصورة اعلاه يمثل مدخل اول طبقة في شبكتنا. اللون الاخضر يمثل مخرج اول طبقة في شبكتنا وطريقة حساب المخرج بتطبيق القاعدة في سطر رقم ٧. ومن ثم اللون البرتقالي يمثل مدخلات ومخرجات الطبقة في سطر رقم ٩ والتي هيا عبارة هن normalization وشرحت المفهوم في مقالة سابقة ومن ثم استدعينها في سطر رقم ٢٨. ذكرت ان المخرج هو نفسه المدخل وهو ٢٨. نكمل الشرح على الصورة؟
سطر ٢٩ استخدمت relu activation function وايضا المدخل نفس المخرج فما اي حسبة جديدة للان. طيب نشوف الان في سطر ١٣ انه عرفت طبقة maxpooling وشرحتها بالتفصيل في مقالة سابقة وقلت حجم الفلتر هو ٢. بعد ذلك استدعيناها في سطر رقم ٣٠. طيب احنا نعرف المدخلات هيا ٢٨ ما تغيرت لكن ما المخرجات لهذه الطبقة؟ هيا نفسها لكن عدد حجم الفلتر المخرج هو ١٤ لان عندي حجم الفلتر الذي اخترناه هو ٢ وبالتالي مدخل الطبقة ٢٨ على حجم الفلتر يعطيني ١٤ كما نرى في القاعدة في سطر رقم ١٤. امشي بالطريقة نفسها على باقي الطبقات.
طيب حجم الفلتر لطبقة maxpooling هو ٧ كما نرى في سطر ٢٠ ونلاحظ الان نبغى نرسل البيانات لطبقة مختلفة وهو linear layer وشفنا قبل في المقالات السابقة ان هذه الطبقة نستخدمها لعملية التصنيف وان المدخلات المطلوبة لهذه الشبكة هو كالاتي: الخانة الاولى عدد الbatches والخانة الثانية ال input features والتي هيا مخرجات الطبقة التي قبلها.
حسب ما تعلمناه في الصورة اعلاه. فان بعد تطبيق القاعدة في سطر ٧ فان ناتج maxpooling هو ٧. والتي هيا عبارة عن الطول والعرض للفلتر. يعني ٧ للطول و٧ للعرض. ونعرف ان مخرجات الطبقة هيا ٣٢ وهيا ناتج حسبة طبقة convolutional layer الاخرى لان نعرف خلاص انه استخدام normalization ما ياثر على مخرج الشبكة. فلو طبقت القاعدة في سطر ٧ على طبقة convolutional layer في سطر ١٦ حتعطينا الناتج ٣٢ عندما نستدعيها في سطر ٣١. وبالتالي الان حتى نحول مخرج هذه الطبقة والذي نعرف انه يحتوي ٤ خانات كما نرى في صورة رقم ٢ وهيا ٣٢ ل N والقناة 1 و الطول والعرض هو 7 .
كيف احول مخرجات طبقة convolutional layer لتتناسب مع مدخلات طبقة linear layer؟
الموضوع سهل بما انه احنا عارفين الحسبة كل الي نسويه نضرب الطول والعرض في المخرج و١ عدد القناة ما ياثر ومن اجل ذلك تجاهلته عند الحسبة كما نرى في سطر رقم ٢١. بالتالي الان نتسخدم دالة view التي شرحتها في مقالة منفصلة كما نرى في سطر رقم ٣٥ ووضعنا ناتج الضرب. واخيرا المخرجات حتكون عندي ١٠ وهيا الارقام من 0 الى 9 كما عرفناها في سطر رقم ٢٤.
ملاحضات مهمة بخصوص هذا القسم الخاص بتعريف الشبكة العصبية التي أنشائنا
اقرا القسم هذا مرة واثنين لتستوعب الموضوع لان الموضوع اسهل مما انت متخيل ولكن الصعوبة ربما ان شرح المفهوم صعب عن طريق الكتابة. ولذلك انشات هذا الفديو ايضا وشرحت نفس المفهوم في حال لم تستوعب ما شرحته هنا كاملا. تستطيع مشاهدة الفديو من هنا
ايضا ممكن تقول في نفسك هل حجلس كل ما بنيت شبكة عصبية احسب كل هالحسبة بنفسي؟ فيه طريقة اسهل وهيا عن طريقة طباعة المخرجات كل مرة مثل ما فعلت في سطر رقم ٢٦ وفي حال كنت تريد مشاهدة تطبيق عملي لما ذكرت. تستطيع ذلك عن طريق مشاهدة الفديو من هنا.
مرحلة التدريب والاختبار
انا ذكرت بالتفصيل في هذه المقالة وقلت ان عند تدريب model نحتاج ٣ مراحل وذكرت تفاصيل كل مرحلة. فاذا كنت مو فاهم ايش يتم في كل مرحلة وليه نحتاجهم انصحك ترجع للمقالة. المراحل التي نحتاجها عند تدريب اي مودل سوا MLP او CNN هيا كالاتي:
Forward pass
Calculate error or loss
Backward pass
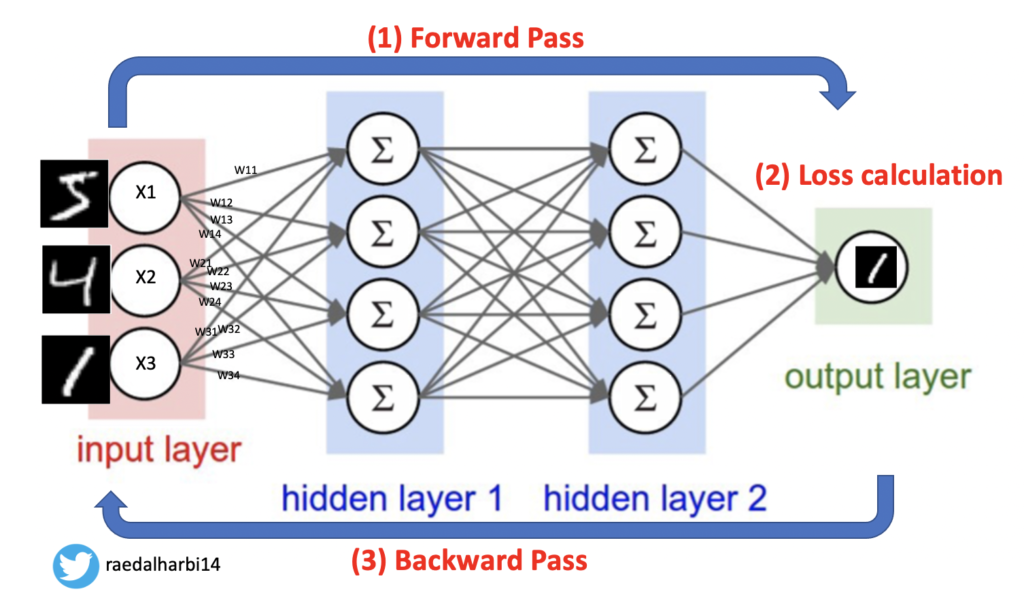
نشوف الصورة التالية ونكمل:
مثل مو ظاهر في الصورة حنبدا وننفذ كل مرحلة بالترتيب. لكن اول شي خلينا نختار loss function التي سنستخدم في المرحلة الثانية. وايضا ما نوع ال optimizer الذي سنستخدمه لتحديث الاوزان كل مرة في المرحلة الثالثة. بالاضافة اكيد الى استدعاء المودل الذي بنيناه. تعال نشوف الكود:
epochs وعدد optimzerو loss function صورة رقم ٤ : تهيئة المودل و
السطر رقم ١ بكل اختصار نقوله اذا جهازك او النظام او السحابة الي انت شغال عليها اذا تدعم cude استخدمه وهو يعطيك GPU عالي وهذا يفيدنا في تسريع عملية التدريب وهذه الميزة موجودة في Google colab pro التي باشتراك شهري ومشترك فيها انا ومن اجل ذلك استخدمها. وفي حال ما عندك cuda، حيستخدم cpu العادي الذي تدعمه قوقل وهو مجاني. بعد ذلك في سطر رقم 5 هيئنا المودل واستدعيناه وقلنا له to(device) والتي تعني باختصار اذا موجود cuda استخدمه. ايضا استخدمنا crossEnropyLoss ك loss function لان تدعم التصنيفات المختلفة وهيا
التي تحسب لنا نسبة الخطأ بين التوقع للمودل الخاص فينا وهو predicted labelsوبين ال labels الحقيقية الموجودة في البيانات. وكذلك استخدمنا SGD ك optimizer مع learning rate 0.01. وشرحت في مقالة سابقة بالتفصيل ال learning rate.
ماهو هدفنا من مرحلة التدريب من الناحية النظرية؟
نوصل للاوزان المناسبة التي تقلل لنا نسبة الخطأ بين توقع المودل وبين قيمة الlabel الحقيقية في البيانات. في المرحلة الاولى: نحسب dot prouct والناتج حيكون توقع وهي الاوزان. المرحلة الثانية: حنحسب نسبة الخطا باستخدام CrossEntropyLoss() واكيد حيكون التوقع في اول مرة خطا لان الاوزان في البداية تكون صفر او عشوائية وبالتالي نسبة الخطا حتكون عالية loss error. بالتالي نروح للخطوة الثالثة ونحدث الاوزان باستخدام gradient decent واستخدمنا هنا SGD. وضحت الصورة؟ ارجع للمقالات السابقة اذا تحتاج توضيح اكثر. نشوف الكود:
صورة رقم ٥ : كود التدريب
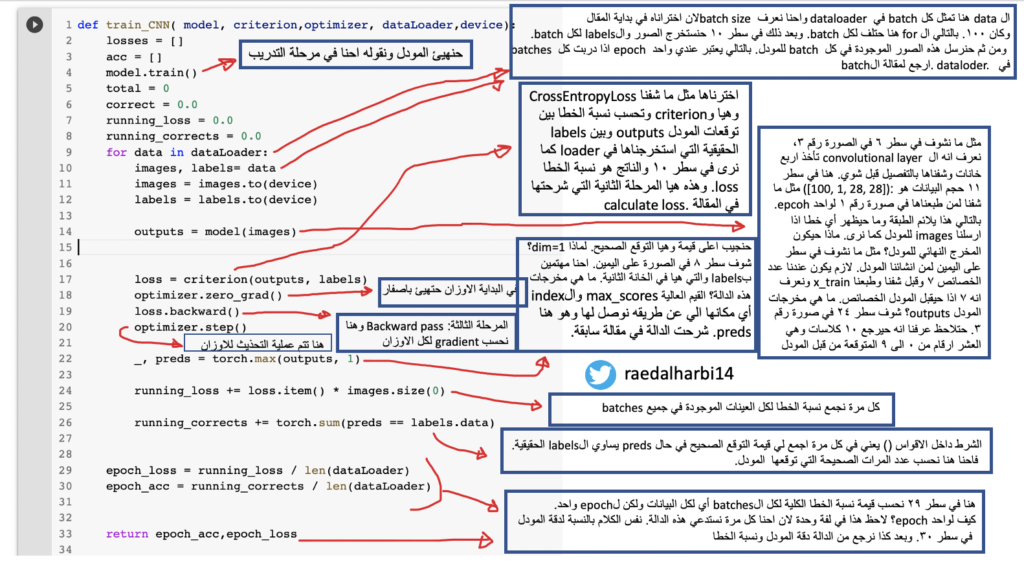
قبل ما نشغل الكود حنفهمه اول شي. في الصورة وضحت كل شي ولكن ابغى انوه اني الى الان ما وريتك ما هي محتويات دالة التدريب train_CNN التي استدعيتها في سطر ١٠ وايضا دالة الاختبار vaildate_CNN في سطر ١٦. المفهوم العام في الصورة اعلاه. احنا حنجلس نلف على عدد ال epcohs الذي اخترناه في صورة رقم ٤ وهو ١٠ مرة وفي كل مرة حنرسل لدالة التدريب: المودل model الذي هينئنها قبل بالاضافة الى train_load والذي عن طريقه حنستخرج البيانات الخاصة بالتدريب وال labels المقابل لها. وبعدها وظيفة الدالة ترجع لي دقة المودل بالاضافة الى نسبة الخطا. طعبا نسبة الخطا كل ما كانت قليلة كانت شي ممتاز والدقة كل ما كانت عالية تدل على انه المودل يتدرب بشكل صحيح. وايضا ارسلنا device حتى نستخدمه وندرب بشكل سريع وجد ال gpu العالي. نفس الكلام ينطبق على دالة الاختبار في سطر ١٦ ولكن مع بيانات الاختبار. وايضا لاحظ انه ما ارسلنا optimizer في دالة الخطا. لماذا؟ لان خلاص احنا دربنا المودل فما عاد نحتاج نحدث الاوزان. تعال الان نشوف دالة بيانات التدريب.
صورة رقم ٦ : دالة التدريب
واضحة الصورة؟ تعال نشوف دالة الاختبار وهيا بالضبط نفس دالة التدريب لكن الفرق انه ما حنحتاج نحدث وبالتالي ما في optimizer بالاضافة الى انه بدال model.train(). وضعنا model.eval() لان نهيئ المودل ونخبره انه احنا في مرحلة الاختبار. نشوف الكود
صورة رقم ٧: دالة الاختبار
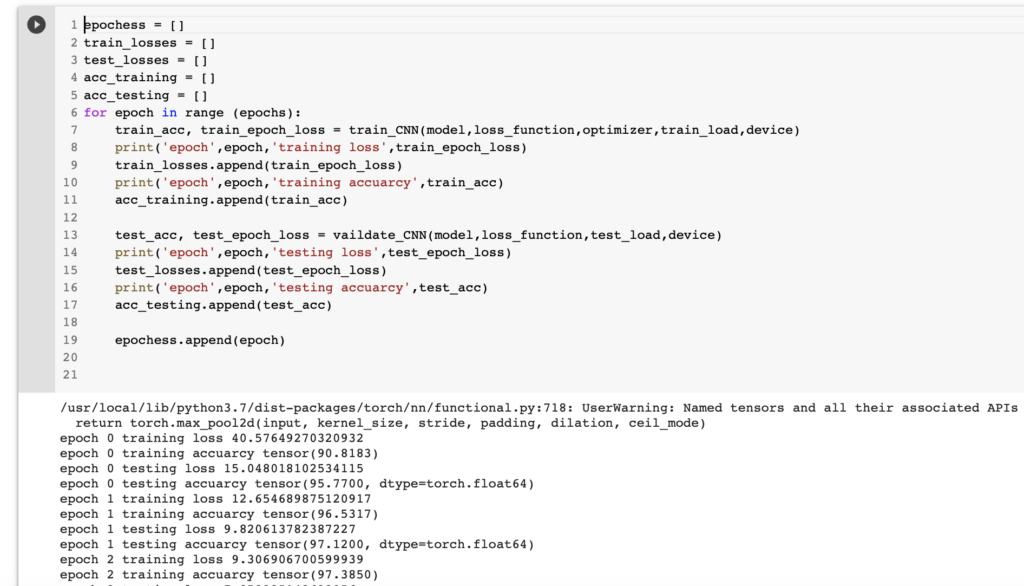
الحين خلينا نرجع للكود في صورة رقم ٥ ونشغله ونشوف جزء من عملية الطباعة
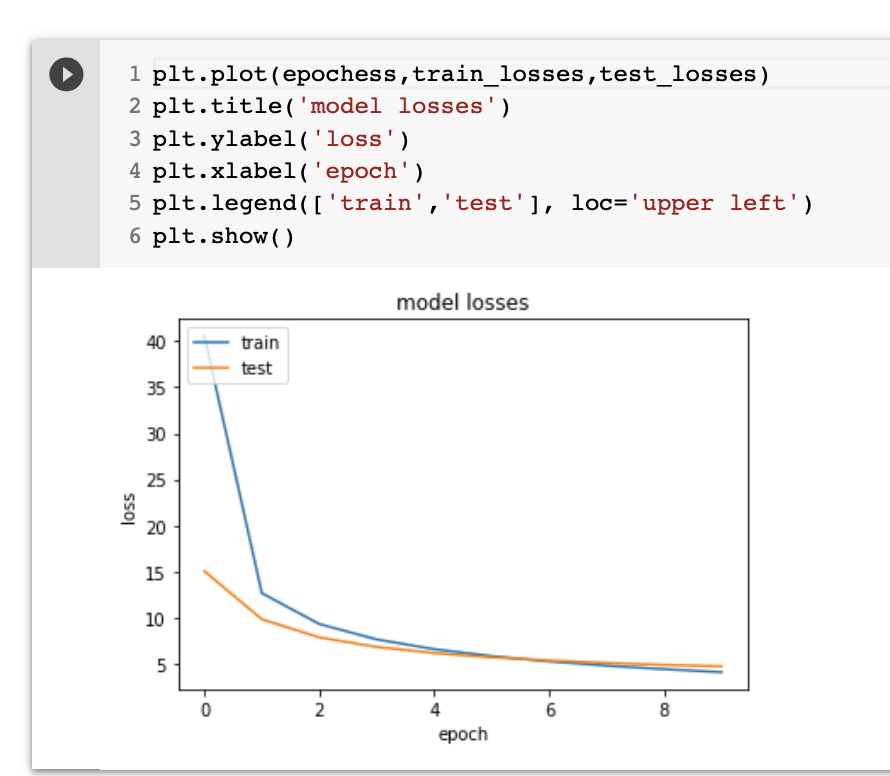
نلاحظ انه جالس يدرب ويطبع لنا نسبة الخطا ودقة المودل. نتركه الى ما يخلص تدريب وبعد ذلك نشوف الدقة ونسبة الخطا ولا تنسى كان ما كانت الدقة عالية كان افضل وكل ما كانت نسبة الخطا قليلة كان افضل. في الصور شرحت وقلت انه انشائنا كم لستة وجلسنا نحفظ النسب لدقة المودل لكل epoch بالاضافة الى نسبة الخطا loss لدالة التدريب والاختبار. ليه؟ نشوف الصورة التالية
epochs صورة رقم ٨: فهم نسب الخطا لكل بيانات التدريب والاختبار لكل ال
اول شي استخدمت مكتبة matplotlib والتي توفر لنا عرض انواع مختلفة للصور وال graph لبياناتنا. في السطر الاول استدعيت المكتبة. الدالة plt.plot تاخذ خانتين الاولى هيا x وفي مثالنا وضعنا اللستة التي تحتوي كل epoches . والخانة الثانية التي هيا y ووضعنا train_losses التي تحتوي على جميع نسب الخطأ في مرحلة وايضا اضفنا نسب الخطا test_losses والدالة حتفهمها كانها y حتعاملها مع x بشكل منفصل.
سطر ٣ و٤ نحن نسمي الاعمدة على x-axis و y-axis. سطر ٥ طبعنا legend الي نشوفه في اعلا الصورة على اليسار. سطر ٢ طبعنا عنوان الصورة. وفي الاخير عرضنا الصورة في سطر ٦..
ماذا تعني الصورة؟
تعني ان المودل الذي انشائنا يتدرب بشكل صحيح. فنلاحظ نسبة الخطا في البداية عند اول 2 epochs كانت عالية ومع مرور اللفات بدات نسبة الخطا تقل. ايضا نسبة الخطا لمرحلة الاختبار تعتبر ممتازة ايضا. نشوف الان ال plot اخر لكن بالنسبة لدقة المودل.
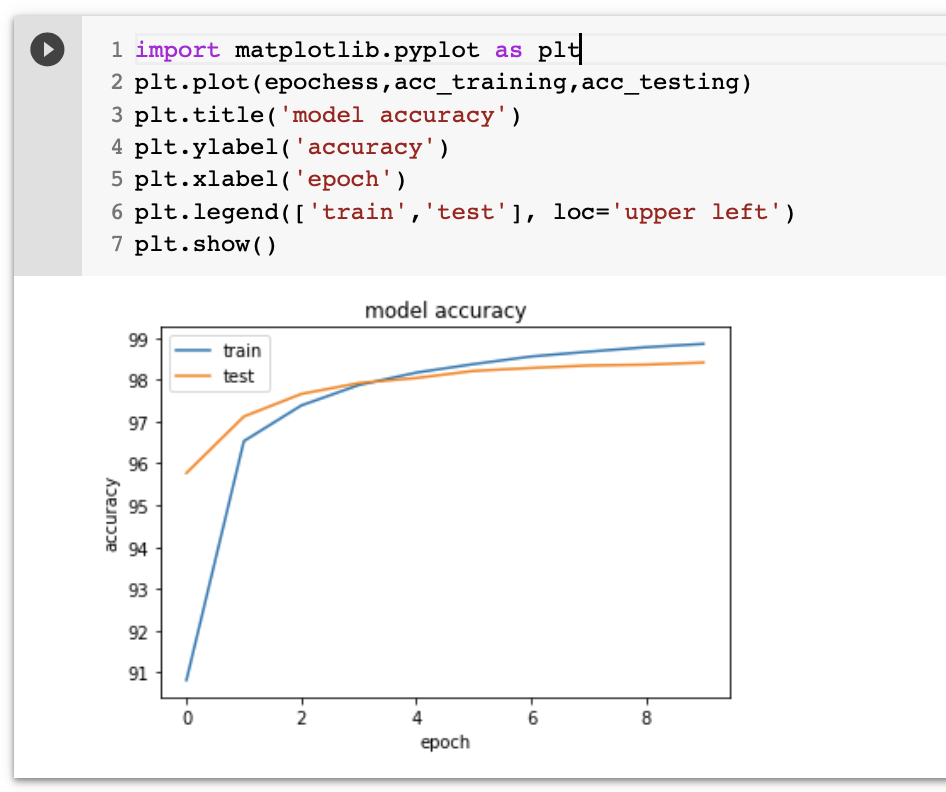
epochs صورة رقم ٩: فهم نسب دقة المودل لكل بيانات التدريب والاختبار لكل ال
هنا نفس الكلام لكن جالسين نشوف نسب دقة المودل خلاص مرحلة التدريب والاختبار لجميع ال epochs. ونلاحظ في البداية في اول لفتين، دقة المودل كانت دقة المودل حوالي ٩١ بالمية في مرحلة التدريب ولكن مع زيادة اللفات زادت دقة المودل. وصلنا اعلى دقة في مرحلة التدريب الى حوالي ٩٩٪ بالمية وتقريبا ٩٨٪ بالمية بالنسبة لمرحلة الاختبار.
حفظ المودل model الذي دربناه
حنشوف الان كيف نحفظ المودل الذي دربناه حتى تستخدمه اي وقت بدال ما ندرب المودل من أول وجديد. بالاضافة الى ذلك حنستدعي نفس المودل هذا الذي دربناه وحنحاول نفهم توقعات المودل ونستوعبها باستخدام SHAP بعد ما نحمل المودل المدرب.
قبل نشوف الكود التالي لكيفية حفظ المودل الذي دربناه، حوريك في الكود التالي كيفية ربط google colab مع google drive بحيث تحفظ المودل المدرب في قوقل درايف. نشوف الكود التالي:
رقم ١٠ : ربط قوقل درايف بقوقل كولاب
شغل الكود. بعد ذلك حيظهر لك الرابط. اضغط على الرابط وحيوديك الى ايميلك. سجل دخول وحتظهر لك الصفحة التالية:
انسخ الكود والصقه في المربع في صورة رقم ١٠. وحيظهر لك مثل الصورة التالية:
Mounted بما معناه انه ربطنا Google Colab ب Goolge drive. الان نشوف الكود لحفظ المودل:
الامر للحفظ هو torch.save وبعد ذلك نضع اسم المودل .state_dict() وفي حالتنا اسم المودل الذي دربناه هو model كما رأينا. وفي الخانة الثانية نضع الرابط لمكان الحفظ ولاحظ اني حفظت المودل على google drive في مجلد اسمه DeepLearning_Course واسم المودل الذي دربناه هو cnn_model.
ان اصبت فمن الله وان اخطات فمن نفسي ..
لا تنسى مشاركة المقالة اذا أعجبتك ..
اخوكم رائد الحربي
ولاي ملاحضات او استفسارات يرجى مراسلتي على تويتر @raedalharbi14 أو كتابة التعليق هنا













Pingback: فهم وتحليل توقع المودل المدرب – شرح تفصيليي – Akadyma Blog
Great , Thanks a lot.
اخوي احتاج مساعده