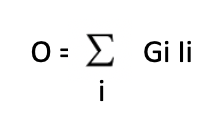تحدثنا في المقالة السابقة عن الفرق بين fully connected network وبين convolutional neural network بشكل عام. وذكرنا ايضا انه الشبكة العصبية CNN عادة تتكون من الطبقات التالية:
Input layer
convolutional (Conv) layer
Pooling layer
Fully connected(FC) layer
Softmax/logistic layer
Output layer
والصورة التالية توضح ترتيب الطبقات layers التي سنتكلم عنها بشكل اوضح.
CNN Network
حشرح في هذه المقالة convolutional layer بشكل مفصل.
أول شي لازم نعرف انه convolutional layer تتكون من شيئين رئيسين وهما:
الفلاتر filters
خريطة الخصائص feature maps
ماذا نعني بالفلاتر filters؟ وما فائدتها؟
ما اعني بالفلاتر هو نفس المعنى اللغوي وهو التنقيح اي ننقح الشي او نفلتره. تعال نشوف كيف شكل الفتلر filter كما في الصورة ادناه.
صورة رقم ١ : فلتر عرضه ٣ وطوله ٣
الفلتر filter في الصورة اعلاه طوله ٣ وعرضه ٣. الان اذا احد اخبرك انه عندي فلتر filter حجمه ٣ على ٣ او مثلا ٥ على ٥ فاعرف انه يقصد طول وعرض الفلتر filter مثل ما رأينا في الصورة رقم ١.
المربع الذي حدده بالاحمر هو مركز الفلتر. ووظيفة هذا الفلتر انه يستخرج لي مجموعة من الخصائص الموجودة في صورة معينة.
طيب الان افرض عندي الصورة التالية:
pixels صورة رقم ٢ : اي صورة تتكون من مجموعة من
طيب مثل ما ذكرت في المقالة السابقة انه اي صورة عندنا تتكون من مجموعة من pixels وهي المربعات الصغيرة التي نراها في الصورة رقم ٢.
ما علاقة ال convolutional operations بالفلاتر؟
الفكرة انه ناخذ الفلتر filter ونمرره على الصورة وهذا يعرف ب window sliding. في مثالنا هذا عندنا فلتر filter عرضه ٣ وطوله ٣ مثل ما نشوف في الصورة رقم ١. نلاحظ انه الفلتر عنده مركز وهو التحديد الذي حدده باللون الاحمر. لو اخدنا هذا الفلتر واسقطناه على الصورة حيكون الناتج مثل ما نرى في الصورة رقم ٢. ونقدر نعرف مكان الفلتر في الصورة رقم ٢ من التحديد باللون الاحمر لمركز الفلتر واللون الازرق للفلتر كامل. نمرر الفلتر في الصورة رقم ١ على جميع انحاء الصورة في صورة رقم ٢. نسقط ونمرر الفلتر على جميع انحاء الصورة. لماذا؟ لان كل فلتر حيستخرج لنا خصائص مختلفة عن الفلتر الاخر من الصورة. مثلا لو عندي صورة سيارة، واسقطنا الفلتر على الصورة ومررناه على جميع انحاء صورة السيارة. فيه فلتر مثلا يستخرج لنا كفر السيارة وفلتر اخر مثلا يستخرج سقف السيارة وهكذا. هالخصائص المستخرجة هيا ما يتعلمه المودل ليفرق بين صورة واخرى.
ملاحضة: نلاحظ انه غالبا الفلتر عنده وزن معين وكذلك ال pixels في الصورة. بالتالي احنا نسوي مشاركة للاوزان اي الاوزان كثير منها مكررة لان حيسير تداخل بين الفلتر اذا اسقطناه في اكثر من مكان في الصورة. وهذا يذكرنا في الميزة الي اتكلمت عنها في المقالة السابقة انه convolutional operations تسمح لي بمشاركة الاوزان بعكس fully connected network وهذا يقلل كمية paramters ويزيد سرعة المودل model في مرحلة التدريب.
رائد انت كررت كلمة “اسقطنا” او “مررنا” كثير. لكن ما شرحت لنا كيف ننفذ عملية الاسقاط او التمرير للفلاتر على الصورة رياضيا؟
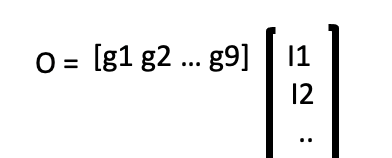
رياضيا اعني فيها عملية الضرب ل two matrices. أي
element-wise multiplication of the two matrices وهيا بالمختصر انه اضرب الفلتر في الصورة. وشرحت فكرة هذه الضرب في احد المقالات العلمية السابقة.
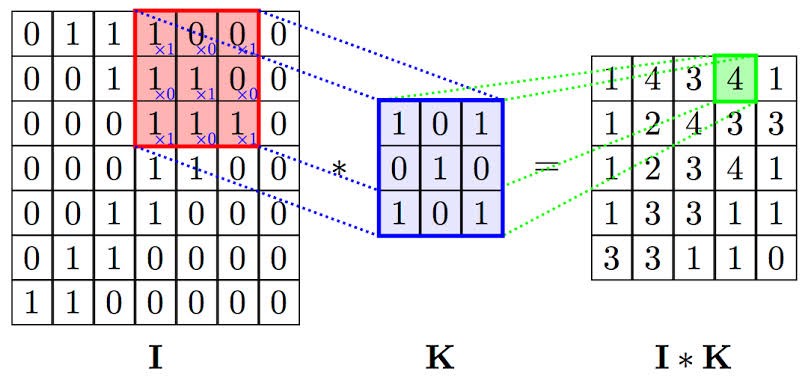
تعال نرى الصورة رقم ٣ مع بعض.
convolutional operations صورة رقم ٣ : طريقة عمل
الصورة على اليمين في صورة رقم ٣ هيا ناتج عملية ضرب الفلتر في الصورة وهو ما يسمى features map.
ما فائدة features map?
خريطة الخصائص تحتوى على الخصائص المستخرجة من قبل الفلاتر. والخصائص استخرجت عن طريق اسقاط او بما معناه ضرب الفلاتر في الصورة. كيف نطبق عملية الضرب بانفسنا؟ مثلا لنفرض نبغى نحسب قيمة الخلية المحددة باللون الاحمر في feature map والتي سميتها o.
نحسبها بالطريقة التالية:
لو حبسطها اكثر حتكون كالاتي:
هذا بالضبط ما ما يسمى ب element-wise multiplication ل two vectors.
يعني بالمختصر ناتج ضربهم.
ماهي مدخلات طبقة convolutional layer؟
لو فرضنا انه اول طبقة في شبكتنا هيا convolutional layer، ففي الحالة هذه المدخلات للطبقة حتكون ال pixels للصورة. ماذا لو كانت convolutional layer في طبقة اعمق؟ في هذه الحالة المدخلات حتكون من feature map الذي قبلها والذي ايضا من الممكن ان يكون نتيجة convolutional layer اخرى.
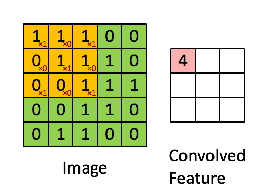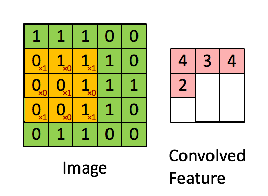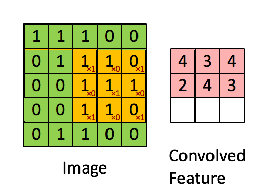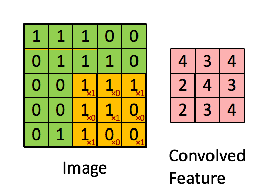
هاذي مثالين اخرين لطريقة عمل convolution operations. واحد ثابت والاخر متحرك حتى نشوف كيف الفلاتر filter تسقط على الصورة في مختلف الجهات. وحاول تختار لك مربع معين في features map وتحسب ناتج عملية الضرب نفس ما اتعلمنا فوق وحتشوف النتيجة هيا نفس النتيجة الموجودة في المربع الموجود في features map.
convolution operations صورة رقم ٤ : مثال اخر لكيفية عمل
صورة رقم ٥: تطبيق الفلتر على الصورة
نلاحظ في الصورة رقم ٤ انه الناتج كان ٤ في الصورة على اليمين. لو طبقنا نفس المعادلة التي ذكرناها حيكون الناتج ٤.
طيب ال feature map او ما يعرف احيان(convolved features) وظيفته انه يحفظ لنا الخصائص المهمة في الصورة بالطريقة التي ذكرنا.
طيب ناتج ضرب الفلتر filter في الصورة يعطينيا feature map والتي تحتوي الخصائص المهمة في الصورة. وكمثال لو عندنا صورة قطة حيستخرج الخطوط الافقية والعامودية ووالخ كخصائص وهالخصائص مع بعضها البعض في الاخير تكون عندي شكل القط.
طيب كيف نكون هالخصائص او نربطها مع بعضها البعض؟
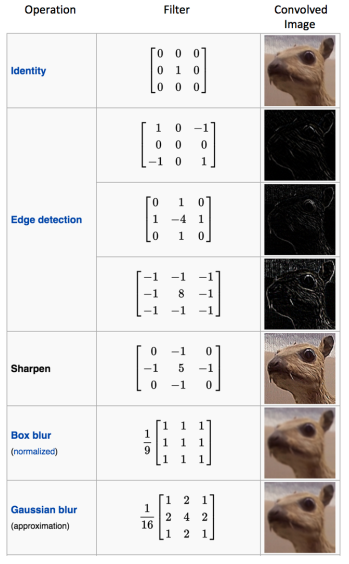
كل فلتر filter يستخرج لي خصائص مختلفة عن فلتر اخر وكل فلتر لها ارقام اكيد. والصورة ادناه مثال بسيط على فلاتر مختلفة وفي المقابل تظهر لك الخصائص التي استخرجها الفلتر. مرة يستخرج الخطوط العامودية من الصورة ومرة الخطوط الافقية ومرة حدة الصورة وهكذا. ما حدخل في الاثباتات الرياضية لكن من المهم تعرف انه الناتج هي الخصائص المهمة في الصورة. وايضا كل filter يستخرج لنا خصائص مختلفة من الصورة وهكذا. وهذا يفسر لماذا نشوف في الجانب العملي انه يكون عندنا اكثر من فلتر filter
صورة رقم ٧ : فلاتر مختلفة تستخرج خصائص مختلفة من الصورة
ملاحضة: في التطبيقات العملية حتشوف المدخل convolutional layer كالاتي:
احنا ذكرنا انه المدخلات ل convolution layer هيا الصورة والتي عيا عبارة عن مجموعة بكسل pixels. والصورة مثل ما نعرف عندها طول وعرض. نفس الكلام ينطبق على الفلتر اذا اردنا ان ندخله كمدخل الى طبقة convolution layer، نحتاج نعرف الطول والعرض للفلتر ايضا. هذا الي اتعلمناه في مقالة اليوم. لكن في التطبيقات العملية حتلقى اضافة اخرى كما نرى في الصورة اعلاه وهي d. فماذا تمثل؟
تمثل d القناة او ما يسمى ب channel.
طيب ماذا تعني القناة channel؟
تعال نرى الصورة التالية اول شي وحشرح لك ما هي القناة او القنوات.
channels صورة رقم ٦ : تطبيق الفلتر على صورة تحتوي
نلاحظ انه الصورة عندي حجمها ٦ على ٦ لكن فيه dimnsion اضافي وهو ٣ والتي ترمز ل channel. نفس الكلام بالنسبة للفلتر بالاصفر.
طيب فكر في ال channel كعمق الصورة زي ما تلاحظ الصورة لها عمق. طيب العمق يرمز لايش؟ هو يرمز للالوان وعندي الالوان نعرف انها تتكون من الاساس من ثلاث الوان رئيسية وهيا ازرق احمر واخضر RGB. يعني اذا شفت channel تساوي ١ فاعرف انه الصور هيا صور رمادية. بمعنى اخر ال channel هيا عبارة عن تمثيل الالوان في الصورة وتكون على شكل عمق.
لمتابعة الفديو الخاص بالمقالة، الرجاء الضغط
هنا
ان اصبت فمن الله وان اخطات فمن نفسي ..
لا تنسى مشاركة المقالة اذا أعجبتك ..
اخوكم رائد الحربي
ولاي ملاحضات او استفسارات يرجى مراسلتي على تويتر @raedalharbi14 أو كتابة التعليق هنا