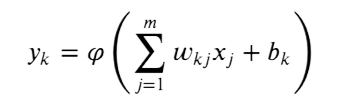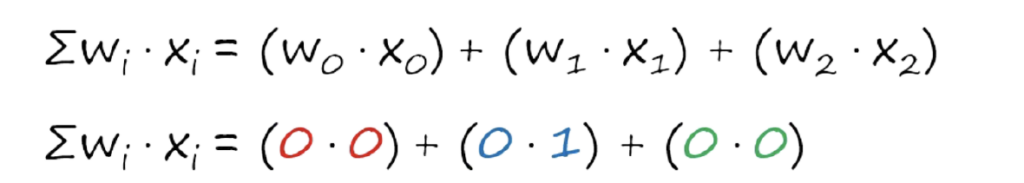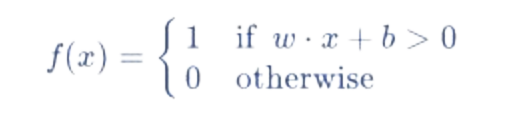مع التقدم السريع في مجال الذكاء الاصطناعي، أصبحنا نرى مختلف التقنيات في وقت وجيز. وعندما نتحدث عن التعلم العميق deep learning فنحن نعني الشبكات العصبية. لكن يبقى السؤال كيف استطيع أواكب كل هذه المتغيرات في المجال؟ وعلى سبيل المثال، نرى شبكات عصبية مختلفة من CNN, RNN, LSTM وغيرها من الشبكات.
من أكثر المعوقات التي تعيقك على الابداع في مجال التعلم العميق هيا تطبيقك الجانب العملي من غير فهم الجزء النظري والرياضي بشكل كافي. الموضوع أسهل مما تتخيل ان شاء الله ولا أبالغ اذا قلت لك انك اذا فهمت الأساس في هذه المقالة، سوف يسهل عليك فهم أي موضوع في التعلم العميق لان الأساس واحد.
هيكل الأنظمة التي تعتمد على الشبكات العصبية
أنظمة التعلم العميق (deep learning) العصبية تتكون من مجموعة متصلة من الوحدات العصبية (neurons) التي تكون منظمة داخل مجموعة من الطبقات (layers) وهي كالاتي:
أ. طبقة المدخلات (input layer): هذه الطبقة هيا المسؤولة عن استقبال المدخلات (initial data) ومن ثم تهيئتها للمعالجة في الطبقات العصبية التي تليها.
ب. الطبقة المخفية (hidden layer): هذه الطبقة تتواجد بين طبقة المدخلات (input layer) وبين طبقة المخرجات (output layer) حيث الوحدات العصبية (neuron units) تقوم بحساب مجموع الاوزان للمدخلات ومن ثم تهيئها للطبقة التي تليها عن طريق دوال تنشيطية (activation functions).
ت. طبقة المخرجات (output layer): وهيا اخر طبقة في الشبكة وهي مسؤولة عن إعطاء النتائج.
أنواع الشبكات العصبية الاصطناعية (Artificial Neural Networks):
معظم الشبكات العصبية الموجودة الان تعتمد على الفكرة الاساسية وهيا perceptron. لنرى ما هيا قكرة perceptron.
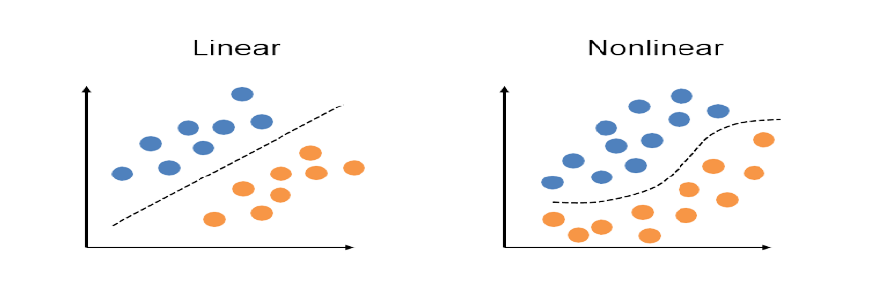
Linear VS Nonlinear : صورة رقم ١
البيرسيبترون (perceptron): وهو من أقدم وابسط النماذج (models) في الشبكات العصبية الاصطناعية (Artificial Neural Networks) ويستخدم كمصنف خطي (linear classifier) لتتوقع وتصنف شيئين ثنائيين مختلفين كما نرى في الصورة على اليسار أعلاه.
أول نقطة نفكر فيها قبل نفكرة في تصميم النموذج model هيا ايش الهدف او المشكلة التي أحاول أحلها؟ هل متوفرة عندي البيانات؟ طيب لنفرض انه عندنا قاعدة بيانات تحتوي على صور خاصة بالقطط والكلاب. ومشكلتنا التي نحاول أن نحلها هيا انه نريد تصميم نموذج model قادر على تصنيف اي صورة اعطيها للمودل ويقول لنا انه هاذي مثلا صورة قط او صورة كلب. تمام؟ بعد فهمنا ما هو المطلوب وما هيا مشكلتنا التي نحاول نحلها، الان اسمح لي ان نفصل في الموضوع اكثر.
أول سؤال يجي في بالك كيف النموذج model يميز بين الصورتين؟
هذا يتم بشكل اوتوماتيكي في الطبقات المخفية hidden layers وحنشوف في المقالات القادمة كيف تتم العملية بالتفصيل. لكن النقطة المهمة التي يجب أن تعرفها الان انه بيانات صور القطط والكلاب التي افترضنا انها موجودة عندنا يجب ان تكون مقرونة ب labels. ماذا تقصد؟ باختصار يعني كل صورة القطط تكون مقابلها عامود vector يحتوي او يبين انه هاذي الصورة تراها صورة قط وهذا نسميه ب label. نفس الشي بالنسبة لصورة الكلاب.
لماذا نحتاج هالخطوة؟
نحتاجها لان النموذج model الذي حنبنيه في النهاية هو الة. بالتالي يجب نقوله في فترة التدريب training phase انه ترا هاذي الصورة التي جاتك كمدخل تراها صورة قط وهكذا. ماذا عن فترة الاختبار testing phase ؟ ما نحتاج نخبر المودل ان الصورة هيا صورة قط لان هذا الذي نتوقع من المودل ان يفعله. في فترة الاختبار احنا فقط نعطيه الصورة والمودل يتوقع لنا ويقول لنا ترا label او الصورة هاذي تراها صورة قط بناء على الصور التي تدرب عليها في فترة التدريب.
عادة ال labels تكون كارقام يعني مثل صفر يرمز للقط وواحد للكلب وهكذا.
طيب الان كل ما علينا ان نفعله انه نعطي المودل model البيانات و عن طريق الطبقات المخفية حيتعرف على الصور ويميز صورة القط من الكلب. طبعا صور القطط لها خصائص features مختلفة عن خصائص features الخاصة بالكلب وهاذي المودل model حيتعلمها من نفسه وحنرى كيف في المقالات القادمة. ملاحظة:الفرق بين التعلم العميق وتعلم الالة وهو انه في التعلم العميق المودل يستخرج الخصائص بنفسه بينما في تعلم الالة احنا بانفسنا نحدد الخصائص.
كيف نصمم model الخاص فينا لتصنيف القطط أو الكلاب؟
انظر للصورة اليسرى في صورة رقم ١ واعتبر النقاط باللون الازرق تمثل القطط والنقاط باللون البرتقالي تمثل الكلاب.
ممكن يجي في بالك طيب كيف اسوي النموذج model هذا من اجل تصنيف البيانات انه اذا كان النقطة زرقاء يعني قطة واذا برتقالية يعني كلب؟
ما الفرق بين الصورتين فوق؟؟
الفرق هو أن الصورة على اليسار تحتوي بيانات القطط والكلاب ولكن نشوف ان البيانات موزعة بشكل بشكل خطي linearly. ماذا تقصد؟
اقصد ان البيانات اذا كانت خطية معناه انه سهل نرسم خط مستقيم او مائل يفصل بين النقاط الزرقاء والبرتقالية لكن اذا كانت البيانات غير موزعة بشكل خطي مثل ما نشوف في الصورة اليمنى في صورة رقم ١، هنا نحن نضطر نرسم خط متعرج حتى نفرق بين النقاط الزرقاء والبرتقالية وبالتالي معناه انه البيانات موزعة بشكل غير خطي.
ماذا يمثل الخط في الرسمة؟
الخط في الرسمة هو النموذج model الذي نريد بناءه لان احنا هدفنا نعرف كيف نفرق بين القطط والكلاب صح؟ فلو أتينا بصورة جديدة في مرحلة الاختبار والمودل لم يرى هذه الصورة من قبل. المودل حيرى الصورة ويرى خصائها، ومن ثم بناء على خصائص الصورة، المودل model حيحدد اذا الخصائص تدل على ان الصورة صورة قط او كلب. لو فرضنا ان الصورة صورة قط وقراها المودل بشكل صحيح. اذن حيصنف الصورة على انها قطة وحتكون الصورة على شكل نقطة ايضا بجانب النقاط الزرقاء التي تمثل القطط وهكذا.
نرجع ل البيرسيبترون.
البيرسيبترون يتعامل فقط مع البيانات الي قابلة للفصل خطيا مثل الصورة على اليسار والمودل model الذي حنبنيه هو الخط في الصورة اليسرى في صورة رقم ١. اما الصورة على اليمين، البيرسيبترون ما يقدر يتعامل معاها ونحتاج نستخدم شبكات متقدمة اكثر مثلا زي CNN وغيرها.
طيب النموذج model الذي سوف نقوم ببناءه هو الخط الذي نراه في الصورة رقم ١ على اليسار. كيف وليه؟ لان الهدف من تدريبنا للنموذج model انه نفصل بين القطط والكلاب. وفي حال جبنا بيانات جديدة المودل حيكون بني على شكل خط وبالتالي البيانات الجديدة حنقارنها مع الخط وهو المودل. اذا فوق الخط يعني قطط واذا تحت الخط يعني كلاب وهكذا.
السؤال المهم، ماذا يعني الخط رياضيا ؟!
في علم الجبر والمعادلات. الخط في الرسمة يمثل المعادلة الخطية التالية:
y = w*x + b
ممكن اشرح هالتفاصيل الرياضية في مقالة منفصلة انه كيف المعادلة هذه تمثل الخط لكن حاليا خليك متاكد من المعلومة ان الخط في الصورة اليسرى في صورة رقم ١ هو يمثل هذه المعادلة.
ذكرنا قبل شوي انه احنا مجرد حنعطي المودل model البيانات وlabels وهذا يتم في طبقة المدخلات وهو عاد يتعلم صح؟
الاكس هنا هيا البيانات الموجودة في قاعدة البيانات والتي في مثالنا هيا صورة القطط والكلاب وهذه الصور تحتوي على الخصائص. طيب يعني x في المعادلة معلومة ولكن y and b مجهولة عندنا.
طيب الان كيف نجيب قيمة w and b؟ وماذا تعني لنا قيمتهم؟
اولا w تمثل الاوزان او ما يعرف ب parameters وهذه القيم مهم جدا تعلمها ومعرفة قيمها. لماذا؟
لان قيمة انه نتعلم الوزن weight w او ما يعرف ب parameters مهمة جدا لان في فترة التدريب المودل حيحاول يتعلم هالقيم ويخليها قريبة من قيم الخصائص لصور القطط مثلا او صور الكلاب. ماذا يعني هذا القرب؟ يعني انه نحاول نوجد قيمة الاوزان التي تسمح للمودل ان يقلل نسبة الخطا بين ما يتوقعه وبين الصورة الحقيقة مثلا صورة القط. وبالتالي معرفة هذه القيم يسمح للمودل بمعرفة الخصائص التي تنتمي لصور القطط او صور الكلاب. وبالتالي لو جبنا صورة جديدة حيعرف كيف يصنفها. طيب الان كيف نتعلم هالقيم؟
عندي خيارين: الأول انه نجلس نجرب ارقام من عندنا الى ما لانهاية ويمكن نوصل للحل ويمكن لا.
الطريقة الثانية عن
Gradient Decent
وهذا ما سنتحدث عنه بالتفصيل في المقالة القادمة.
ماهو الهيكل العام للبيرسيبترون او اي شبكة عصبية؟
لان ذكرت لكم في البداية كل الشبكات العصبية اساسها واحد ..
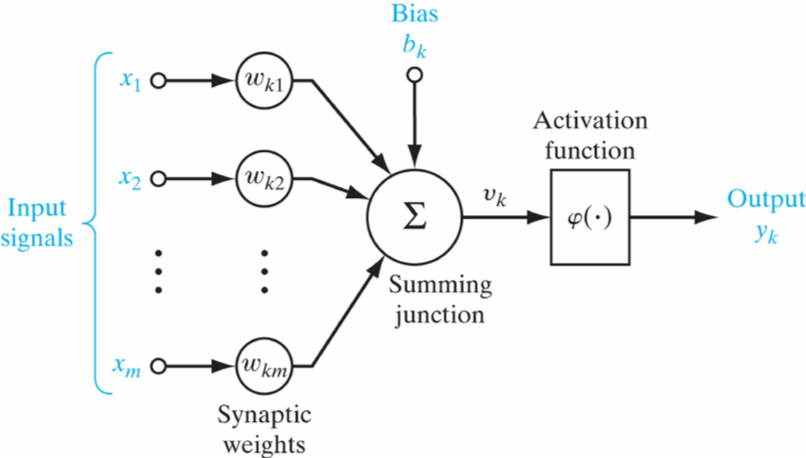
الهيكل العام للبيرسيبترون هو كالصورة التالية:
Perceptron صورة رقم ٣ : الهيكل العام ل
ورياضيا نعني بها التالي:
صورة رقم ٤: المعادلة الخطية
هل الهيكل العام غير واضح؟ وأيضا المعادلة الرياضية؟
لا تقلق الموضوع أسهل مما تتصور.
اولا المعادلة الخطية هيا نفسها المعادلة الي ذكرناه في مثالنا السابق
لكن الفرق في علامة الجمع و activation وسنرى ما هيا.
أ- ماذا أعني ب (input signals) والتي هيا مجموعة من X في الصورة رقم 3؟
.أعنى فيها المدخلات أو الخصائص لكن ماذا ممكن أن تكون المدخلات أو الخصائص؟
X3 وX2 و X1
هيا عبارة input feature space وهيا الصور والتي تحتوي الخصائص التي نتعلمها لنصنف ومثال على ذلك لو اعطينا المودل صورة قط وقلنا له هذا قط وأيضا اعطيناه صورة كلب وقلنا له هذا كلب. المدخلات حتكون مرة صورة القط ومرة صورة الكلب وطبعا الصور تحتوي على خصائص مثل شكل القط او الكلب او لونه او او الخ وكل واحد عنده خصائص تميزه وهذا ما سيتعلمه النموذج (model).
ب- ماذا أعني ب (weights) في الصورة رقم 3؟
الأوزان (weights) هيا قيم عشوائية تعطى لكل مدخل x. يعني كل اكس (خاصية) لها قيمة weight value خاصة فيها. واحنا نعرف انه قيمة x عندنا معلومة لانها الصور .
ت- ماذا أعني بعلامة ∑ الجمع (summation junction) أو تسمى في كثير من الكتب ب (weighted inputs or summation activation) ؟
بكل اختصار هيا معناها أن نضرب كل x بقيمة w المرتبطة فيها وبعدها نأخذ جمعهم. يعني
x1*wk1 + x2*wk2 وهكذا والعلامة تعني جمعهم. و bias حاليا اعتبره كقيمة weight عادية وهكذا نتعامل معاه برمجيا. علامة الضرب هنا اعني فيها dot product. والدوت برودكت dot product تحدد لنا كمية التشابه بين قيمة w و x او بمعنى اخر قد ايش قيمة w قريبة من x. لان مثل ما ذكرنا احنا نبغي المودل يتعلم قيمة w بحيث نخليها قد ما نقدر قريبة من قيمة x الحقيقة في فترة التدريب. والسبب؟ حتى يعرف يصنف اي صورة جديدة بناء على قيم الاوزان التي تعلمها. طبعا ناتج هذا الضرب يعطيني y مثل ما نشوف في المعادلة و y هو ال label الذي توقعه المودل الخاص فينا او بمعنى اخر نتيجة الضرب dot product هو التوقع للمودل.
طبعا في البداية w حتكون قيم عشوائية فبالتالي اكيد label المتوقع من قبل المودل حيكون خطأ. يعني ممكن تعطيه صورة قط ويقولك هذه صورة كلب. يعني لو الصورة التي اعطيناها للمودل كانت صورة قط وال label لها هو صفر. المودل ممكن يتوقع 1 . هنا يجي دور دالة الخطا وهيا انه نحسب فرق الخطا بين الlabel الحقيقي للصورة وبين label المتوقع من قبل المودل الخاص فينا.
وبعد حساب نسبة الخطأ حيروح المودل ويحدث قيمة w عن طريق gradient decent وهذا ما يعرف ب backpropagation وهكذا حتى نخلي نسبة الخطا اقرب ما تكون للصفر.
ت- ماذا أعني ب (activation function) في الصورة رقم 3؟
فكر فيها كأداة تفعل في حال تحقق شرط معين في (Perceptron). عندنا أنواع كثيرة ومختلفة من
(activation functions) نوضحها كالاتي:
Activation Functions صورة رقم ٥: أنواع
حناخذ مثال لنوضح كيفية عملها.
مثال لتوضيح الفكرة. اذا كانت ناتج احد الوحدات العصبية هو x= 0.5 . فمثلا لو استخدمنا activation function رقم1 من الأنواع فوق في صورة رقم ٥. بناء على مثالنا الناتج سوف يكون ١ لان 0.5 والتي هيا قيمة اكس اكبر من الصفر ولو كانت قيمة اكس تساوي -0.8 مثلا سوف يكون الناتج صفر وهكذا.
صورة رقم ٤ هيا المودل model الذي نريد بناء ومثل ما ذكرنا انه يمثل الخط في الصورة اليسرى في صورة رقم ١.
الان بعد ما شفنا الاساسيات بالتفصيل.
مثل ما ذكرت لكم سابقا حذكر لكم الخطوات المتبعة في اي نموذج model خاص بالتعلم العميق. الان حعطيك الملخص لكيفية تدريب اي مودل بشكل مبسط وعلى شكل خطوات.
الخطوات المتبعة غالبا لاي نموذج model في التعلم العميق:
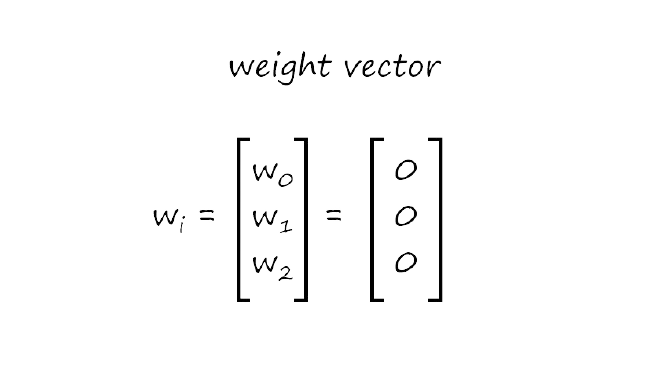
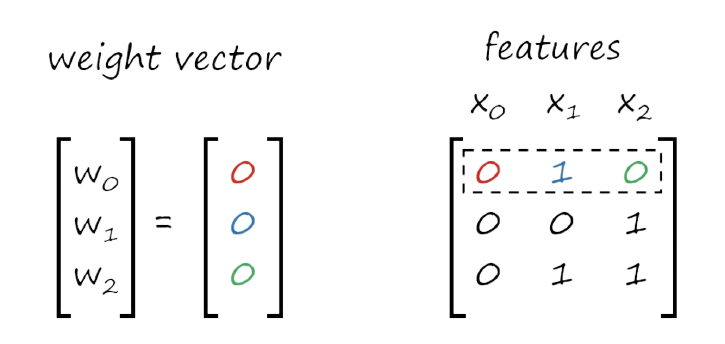
تهئية الاوزان weights: ممكن تكون عشوائية وممكن اصفار وفي مثالنا هذا حنخليها اصفار مثل ما نشوف في الصورة التالية:
الان حنسحب ال dot product يعني حنضرب المدخلات وهيا x وعندنا هيا الصور في ال weights والي هيا القيم العشوائية.
طيب كل صورة مثل x0 عندها مجموعة خصائص وتكون ارقام فحيكون عندنا مثل الصورة التاية :
وبعد ذلك نضربها في بالضبط مثل ما شفنا في صورة رقم ٤ فحتكون النتيجة كالاتي:
اختيار activation function كما في صورة رقم ٤ : في مثالنا حنستخدم دالة بسيطة جدا وهيا كالاتي:
نفس ما شرحتها قبل شوي. اذا تحقق الشرط تعطينا ١ واذا ما تحقق تعطينا صفر. السبب لان احنا ذكرنا في مثالنا انه عندنا يا قطط يا كلاب فحنرمز لها يا صفر يا واحد.
دالة الخطأ Cost Function :
هنا دالة الخطا بسيطة وهيا الناتج من الخطوة اعلاه اذا كان صفر وكان القيمة الحقيقة لlabel هيا صفر ايضا فالتوقع predction كان صحيح وهكذا لجميع العينات. طيب في حال كانت التوقع خاطئ؟ هنا نحتاج نحدث ونسوي عملية ما يعرف backpropagation
Backpropagation: وهنا نحدث الوزن الى ان نصل الئ القيمة الحقيقة الموجودة في label مثل ما حنرى في المقالة القادمة. معادلة التحديث حتكون كالاتي:
حيث الوزن الجديد حيكون يساوي الوزن القديم بالاضافة الى learning rate ونضربه في الشي المتوقع من قبل المودل الخاصة فينا في حال كان خطا ناقص القيمة الحقيقة م label ونضربها في الخاصية. ونكرر الخطوة الين نوصل للحل. التفاصيل حنراها في المقالة القادمة.
ان اصبت فمن الله وان اخطات فمن نفسي ..
لا تنسى مشاركة المقالة اذا أعجبتك ..
اخوكم رائد الحربي
ولاي ملاحضات او استفسارات يرجى مراسلتي على تويتر @raedalharbi14 أو كتابة التعليق هنا