تحدث عن
Gradient decent
بالتفصيل في المقالة هذه . في المقالة هذه حشرح بالتفصيل
learning rate.
ما هو
learning rate
؟ وهل هو قيمة ثابته لاي مودل model ؟ ما علاقته ب
Gradient decent
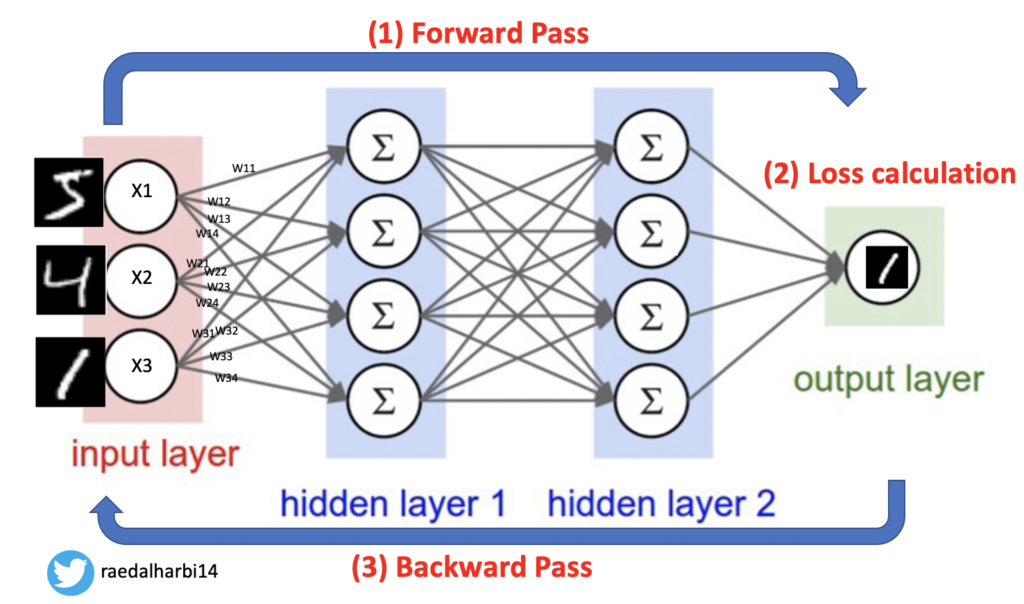
ال learning rate هو معدل التغير ووظيفته انه يوازن لنا بين الاوزان weights و loss function. تعال نسترجع شوي بعض مما ذكرنا في المقالات السابقة ونوصل الصورة كاملة. افرض انه بنبني شبكة CNN تقوم بتصنيف الارقام. في مثالنا هذا المدخلات inputs حتكون مجموعة من الصور وتحتوي على ارقام مختلفة من ٠ الى ٩ زي ما نشوف في الصورة ادناه رقم ١.
والمخرج النهائي output حيكون انه يصنف لي الرقم الي تحتويه الصورة.
الشبكة العصبية CNN او غيرها من الشبكات تتكون من ثلاث خطوات رئيسية مثل ما نرى في الصورة اعلاه:
Forward pass
Calculate error or loss
Backward pass
خلينا نتكلم عن كل خطوة بالتفصيل. أول شي افرض انه عندنا البيانات متوفرة وهيا عبارة عن مجموعة من الصور وكل صورة رقم مرتبطة ب
label
خاص فيها من أجل الشبكة تعرف انه الخصائص المعينة ل
label
المعين. وخلال مرحلة التدريب احنا حنمرر المدخلات مع labels
الخاصة فيها من أجل شبكتنا تتعلم.
Forward pass:
ما الهدف من هذه المرحلة؟ الهدف انه احنا نضرب قيم المدخلات X وهي الصور بقيم الاوزان w التي نريد ان نتعلم قيمها لان نريد قيم الاوزان weights w اقرب ما تكون لقيم الخصائص في الصور حتى لو اعطينا المودل صور جديدة حيضرب قيم الصورة الجديد ب w التي اتعلمها في مرحلة التدريب وبالتالي يصنف او يتوقع ال label للصورة بشكل صحيح.
طبعا في البداية قيم w حتكون مهئية بقيم عشوائية. بالتالي اذا ضربنا او بما معناه نفذنا forward بين جميع x و w لجميع الطبقات حتى نوصل للنهاية مثل ما نشوف في الصورة اعلاه.
يعني بالمختصر نمشي من اليسار الى اليمين جهة المخرجات.
ما معنى هالكلام بالتفصيل؟
المعنى انه نربط بين طبقة المدخلات input layer مع الطبقة المخفية الاولى hidden layer ومن ثم الطبقة التي بعدها حتى نصل للمخرجات.
أكيد بتسال كيف طريقة الربط؟
الطريقة انه نضرب فقط والضرب اعني فيه dot product وهي باختصار يعني اضرب جميع قيم x في w حتى نصل النهاية. وبعد ذلك نحسب activation function.
تعال ناخذ مثال من الصورة فوق. لو نظرنا الى الوحدة العصبية الاولى في الطبقة الاولى، حتكون نتيجة الحسبة كالاتي:
activation function
(x1w11+x2w21+x3w31) ok
يعني ناتج الوحدة العصبية حيكون انه نحسب
dot product لجميع المدخلات
ونطبق نفس الكلام على الوحدات العصبية المختلفة في الطبقات المختلفة.
طيب يكون بعدين وصلنا للمخرجات صحيح؟ وربطنا بين الطبقات المختلفة. وبعدين؟ هنا يجي دور الخطوة الثانية.
Calculate error or loss:
طيب احنا للحين وصلنا للمخرجات يعني نتيجة الضرب تعطينا ال label المتوقع من قبل المودل. لا تنسى في البداية قيم w عشوائية بالتالي نتيجة التوقع حتكون خطأ. لنفرض
انه مررنا للشبكة الصورة رقم ٥
مع label
الخاص فيها وهو ٥.
والشبكة توقعت لي الصورة رقم ٥ انها تنتمي للكلاس رقم ٧ او بمعنى اخر توقعت
label الخطأ وهو رقم ٧.
توقعت لنا الرقم بشكل خاطئ ايش السبب؟ لان زي ما ذكرنا قيم
w
في البداية هيئناها بقيم عشوائية. فالشبكة الى الان ما اتعلمت.
نتأكد كيف؟ نحسب نسبة الخطا باستخدام loss function او احيان تسمى loss error وهي نسبة او فرق الخطأ بين label الحقيقي الموجود في البيانات وبين label الذي توقعه المودل الخاص فينا وهو ناتج dot product او element wise multiplication. اذا كان فرق نسبة الخطأ كبير فاحنا نحتاج نقلل هذه النسبة. كيف نقللها؟ عن طريق تحديث قيم الاوزان بقيم افضل. كيف يتم هذا؟ عن طريق الخطوة الثالثة.
Backward pass:
طيب اعرفنا انه قيمة
w
عندنا خطا فنبغى نحدثها. فالطريقة نحدثها باستخدام المعادلة التالية الخاصة
Gradient Decent كالاتي:
ماذا يعني هالكلام؟ يعني انه احنا نرجع للوراء مثل ما نشوف في الصورة رقم ٣. وهذه العملية تسمى backpropagation. يعني احنا نبدا نحدث كل الاوزان في كل طبقة عن طريق gradient decent الذي يتم العملية عن طريق الاشتقاق. حيث يحاول ال gradient decent يوجد قيمة الاوزان التي تقلل نسبة الخطأ. نرجع الان الى learning rate.
قلنا في بداية المقال ان learning rate يوازن لنا بين الاوزان و loss function. الان حتوضح الصورة اكثر. ما قصدته بعملية الموازنه هو ان learning rate يحدد لنا حجم كمية المسافة التي نقطعها للوصول الى القاع؟ كيف؟ ذكرت في مقالة gradient decent ان الهدف منه ان يساعدنا في ايجاد قيم الاوزان weight التي تقلل نسبة الخطا بين ال label الحقيقي الموجود في بياناتنا وبين label المتوقع من قبل المودل. وال gradient decent يستخدم الاشتقاق او بما معناه انه ننزل للقاع للوصول لهذه القيم. رياضيا معناه انه نوجد القيم التي تقلل نسبة الخطا في الدالة.
ما علاقة هذا ب learning rate؟
علاقته انه اذا كان كمية او رقم learning rate كبير، فاحنا ممكن نتعدى القاع وهذه مشكلة ونفس الكلام لو كان الرقم صغير جدا، هذا معناه ممكن تدريب المودل يستغرق ايام وممكن شهور حتى يوصل للقاع والذي معناه انه وجدنا قيم الاوزان التي تقلل لنا نسبة الخطا.
معدل التغير او learning rate هو قيمة متغيرة وليست ثابته . بمعنى انه لا يمكن يكون عندي رقم محدد للمتغير learning rate وهذا الرقم تستخدمه نفسه في كل models. مثلا افرض انك بنيت مودل model خاص فيك وكان learning rate = 0.1 وكان هالرقم ممتاز. كيف عرفت؟ افرض مثلا انه انعكس عليك في اداء المودل واعطاك accuarcy عالي. هذا الرقم ما تضمن يقودك الى accuarcy عالي في مودل اخر. ولهذا السبب سمي ب hyperparameter اي بما معناه انه الرقم متغير على حسب المودل. وال learning rate عادة تكون قيمته ما بين 1 و 0. تعال الان نرى الصورة التالية ونحاول نفهم بتفصيل أكثر ما التأثير لو اخترنا learning rate كقيمة عالية او صغيرة.
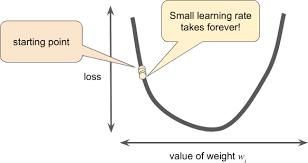
Learning Rate صورة رقم ١ : تاثير اختيار قيمة صغيرة ل
أول شي على
y-axis
نشوف مكتوب
loss
وهيا نفس ما تحدثت عليه قبل شوي اي حساب نسبة الخطا
loss or cost function
بين label المتوقع من قبل المودل وlabel الحقيقي من البيانات .
وايضا نلاحظ على
x-axis قيمة الاوزان المحدثةوهيا المعادلة الي شرحناها.
طيب اذا هيئنا او اعطينا learning rate قيمة صغيرة جدا نلاحظ مثل ما نشوف في النقاط الصفراء انه يتحرك بشكل بطئ جدا. او بمعنى اخر، مقدار حركة learning rate للاسفل بطئية جدا والسبب انه اخترنا قيمة صغيرة جدا لان هدفنا في النهاية نوصل للقاع في اسفل الصورة. ليش هدفنا نوصل للقاع؟!احنا عندنا هدف اساسي وهو انه نحاول نتعلم قيمة الاوزان weights الي تقلل لي نسبة الخطا.
لا تنسى انه احنا في كل مرة نحدث قيمة الاوزان نروح مرة اخرى ونحسب قيمة الخطا بين القيمة المتوقعة من المودل الخاص فينا وبين القيمة الحقيقة من قاعدة البيانات واحنا نبغى هالقيميتين اقرب ما يكونون لبعضهم البعض عشان يكون المودل الخاص فينا تعلم يحاكي ويتوقع نفس البيانات التي تتدرب عليها.
ممكن يجي في بالك كيف يتم اختيار الوزن المناسب لنقلل من نسبة الخطأ؟
عندي حلين الاول انه اعطي بيانات عشوائية من عندي وفي هالحالة حنجلس نحاول الى ما لا نهاية وبالتالي ما نقدر نوجد قيمة الاوزان الحقيقية.الحل الاخر باستخدامgradient decent.وشرحته بالتفصيل في المقالة المتعلقة ب gradient decent. طيب ماذا لو وضعنا قيمة learning rate كقيمة كبيرة كما في الصورة رقم ٢ ادناه؟
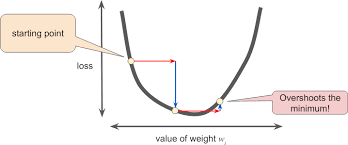
Learning rate صورة رقم ٢ : مدى تاثير اختيار قيمة كبيرة ل
في حال اختيارنا لقيمة كبيرة ل learning rate
حنتجاوز القاع وهيا المكان الذي نريد ان نوصل له مثل ما نرى في الصورة رقم ٢ لان اذا وصلنا للقاع، المودل الخاص فينا حيتعلم وبالتالي حينعكس على دقة المودل accuarcy.ما السبب؟ لانه وجد الاوزان المناسبة.
والحل؟ كيف نختار قيمة learning rate للمودل الذي تشتغل عليه انت؟
الحل انك تجرب اكثر منlearning rate وتختار الرقم الي يعكس دقة عالية للمودل model الخاص فيك. وفيه منهجيات كثير نحاول من خلالها نجد افضل او انسب learning rate للمودل الذي انت تشتغل عليه وحنرى بعض الطرق في الجانب العملي.
لمتابعة الفديو الخاص بالمقالة، الرجاء الضغط
هنا
ان اصبت فمن الله وان اخطات فمن نفسي ..
لا تنسى مشاركة المقالة اذا أعجبتك ..
اخوكم رائد الحربي
ولاي ملاحضات او استفسارات يرجى مراسلتي على تويتر @raedalharbi14 أو كتابة التعليق هنا