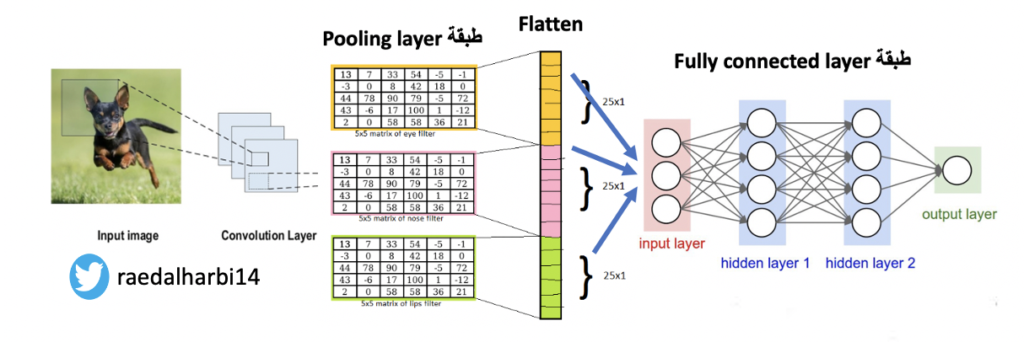
ذكرنا في المقالات السابقة انه الشبكة العصبية CNN عادة تتكون من الطبقات layer الرئيسية التالية:
Input layer
convolutional (Conv) layer
Pooling layer
Fully connected(FC) layer
Softmax/logistic layer
Output layer
والصورة التالية توضح ترتيب الطبقات layers التي سنتكلم عنها بشكل اوضح.
CNN Network
في المقالة السابقة شرحت convolutional layer بشكل مفصل. في المقالة هذه حشرح ال pooling. أول نقطة لازم نعرفها انه عادة احنا نستخدم pooling layer بعد ال convolutional layer. لماذا؟
حنعرف كيف لكن خلينا نستذكر مع بعض من المقالة السابقة ماهي مخرجات convolutional layer. مخرجات ال convolutional layer هيا featurs map والتي تحتوي على الخصائص المستخرجة من صورة معينة عن طريق الفلاتر filters. وعن طريق هذه الخصائص الشبكة العصبية تميز صورة عن غيرها.
لماذا عادة تاتي ال pooling layer بعد convolutional layer؟
بعد ما استخرجنا مختلف الخصائص عن طريق ال features map في convolutional layer.يأتي دور pooling layer والتي تحافظ وتحفظ اهم الخصائص الموجودة.
ممكن يجي في بالك على أي أساس تحدد الخاصية الأهم؟
كل طريقة تختلف عن الاخرى وعندنا هناك نوعين مشهورة من pooling layer وهي كالاتي:
Average Pooling Layers.
Max Pooling Layers.
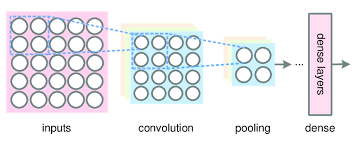
في pooling layer احنا فقط ننفذ down sampling. ماذا تقصد؟ يعني احنا ننقص عدد العينات او البيانات الي ناخدها من convolutional layer والتي هيا الطبقة التي قبلها. والصورة التالية توضح لك كيف احنا انه فعلا نقصنا عدد العينات
pooling layer صورة رقم ١ : طريقة عمل ال
ما الهدف انه نقلل عدد العينات او البيانات؟
الهدف انه نرفع اداء الخورزمية المستخدمة واعني فيها انه العملية الحسابية عندنا تكون سريعة جدا ومو معقدة لان احنا نقصنا عدد البيانات او العينات. الهدف الثاني احنا مو فقط ننقص عدد البيانات بس احنا بالطريقة هاذي ناخذ العينات او البيانات المهمة فقط. ماذا يعني هذا؟ يعني ناخذ الخصائص الاكثر اهمية في الصورة ونتجاهل باقي الخصائص. تمام؟
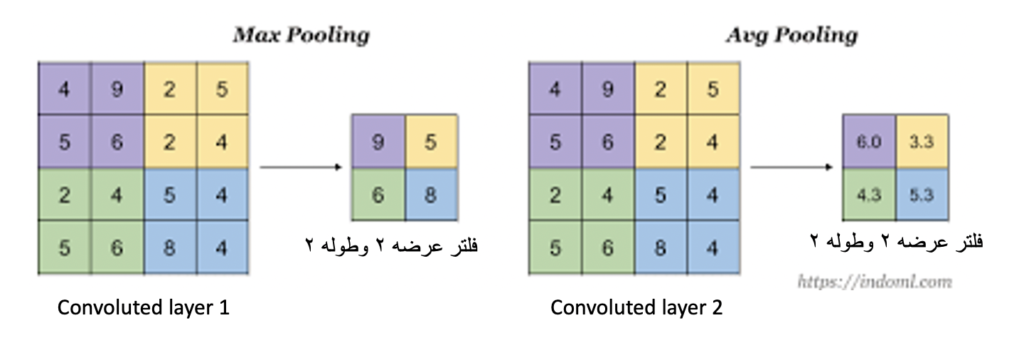
تعال الحين نشوف كيف نحسب pooling layer وذكرت قبل شوي انه عندنا نوعين وهيا max pooling layer and average pooling layer. خلينا نتمعن الصورة التالية ادناه:
Max pooling VS Avg pooling صورة رقم ٢ : الفرق بين
في الصورة اعلاه، الجهة اليمين تمثل النوع الاول average pooling والجهة اليسار تمثل النوع الثاني وهو max pooling. في كلا النوعين احنا نحتاج فلاتر filters. والفلتر اعتبره وعاء له طول وعرض احنا نحددهم ونستخدمه حتى نحدد الكمية التي حنضع فيها البيانات.
نرجع للصورة رقم ٢ ونشرحها بالتفصيل. وحنبدا بالنوع الاول وهو average pooling. ولاحظ عندي مربع كبير مكتوب عليه convoluted layer 2. هذا هو نفسه ال feature map لكن فقط اخترت اسم مختلف لان ممكن تقابلك هالمسميات في مقالة او كتاب اخر. يعني ال feature map الذي نراه هو مخرج طبقة convolutional layer والذي يحتوي على خصائص مختلفة. الان اخترنا فلتر وحددنا طول وعرضه ب٢. الان هذا الفلتر نسقطه على ال feature map وبالتالي سارت عندنا مثلا المنطقة باللون الاصفر محدددة وهي طولها ٢ وعرضها ٢. الان هذه المنطقة المحددة من قبل الفلتر نجيب المتوسط لها. اي بمعنى اخر نجمع الارقام التالية ٢+٥+٢+٤ ومن ثم نقسمها على عددها وهو ٤ والناتج حيكون ٣.٣ كما نشاهد في الصورة على اليسار. باستخدام طريقة المتوسط احنا نحدد اهمية الخصائص باخذ متوسط الخصائص.
نفس الكلام ينطبق بالضبط على النوع الثاني وهو max pooling ولكن الفرق انه بدال ما ناخذ المتوسط، احنا ناخذ اكبر قيمة. ناخذ مثال . القي نظرة على الفلتر المحدد في features map باللون الازرق حتجد انه اخذنا ٨ لانها اكبر شي. بالتالي احنا هنا اخذنا اهم الخصائص عن طريق اخذ الرقم صاحب اعلى قيمة.
لمتابعة الفديو الخاص بالمقالة، الرجاء الضغط
هنا
ان اصبت فمن الله وان اخطات فمن نفسي ..
لا تنسى مشاركة المقالة اذا أعجبتك ..
اخوكم رائد الحربي
ولاي ملاحضات او استفسارات يرجى مراسلتي على تويتر @raedalharbi14 أو كتابة التعليق هنا