بعد ما رأينا في المقالة هذه بالتفصيل ال mltulayer preceptron. في هذه المقالة حنطبق ما تعلمناه على مشروع.
وابغى أوضح نقطة مهمة: هدفي من المشروع ليس بناء مودل model قوي. لكن هدفي تطبق ما تعلمته في المقالات السابقة بحيث تفهم كيف كل شي ماشي وكيف الطريقة الصحيحة لبناء شبكتك العصبية وكيف تفهم مدخلات ومخرجات شبكتك وكيف تدرب وتختبر المودل بطريقة صحيحة. تعال خلينا نبدا
ماهو الهدف من المشروع؟
الهدف هو بناء مودل multilayer perceptron model يقوم بتصنيف اذا ما كانت المريضة مصابة بمرض السكري أو لا بناء على تشخيص حالة المريض الصحية.
ما هيا البيانات المستخدمة؟ وكيف نتعلم منها؟
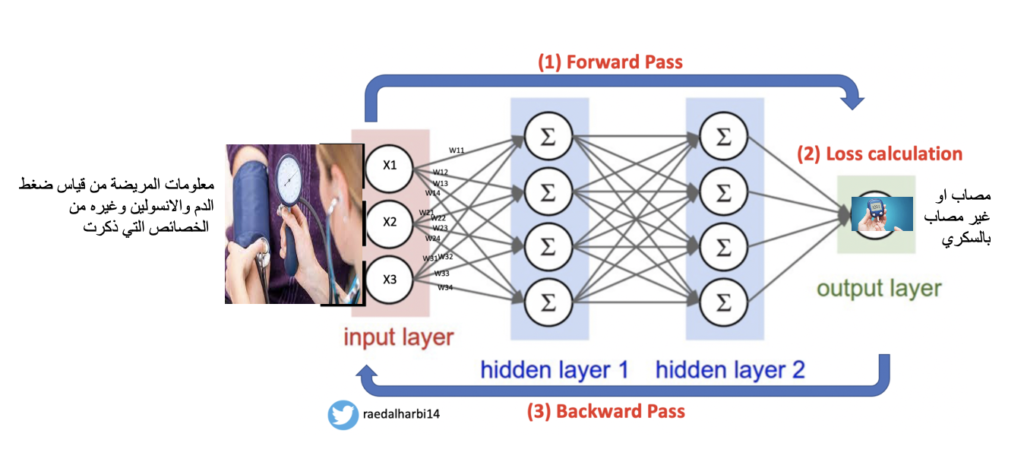
البيانات التي حنستخدمها هيا من المعهد الوطني للسكري وأمراض الجهاز الهضمي والكلى في الولايات المتحدة الامريكية وتحتوي على الخصائص التالية: عدد مرات حمل المريضة، عمرها، ضغط الدم، سمك جلد المريضة، مستوى الانسولين في الدم، مؤشر كتلة الجسم، تاريخ العائلة المرضي للسكر. بالاضافة الى ذلك تحتوي على الكلاس labels والذي يحتوي قيميتن وهيا مصاب positive او غير مصاب negative.
تعال نشوف الصورة التالية ونفصل أكثر.
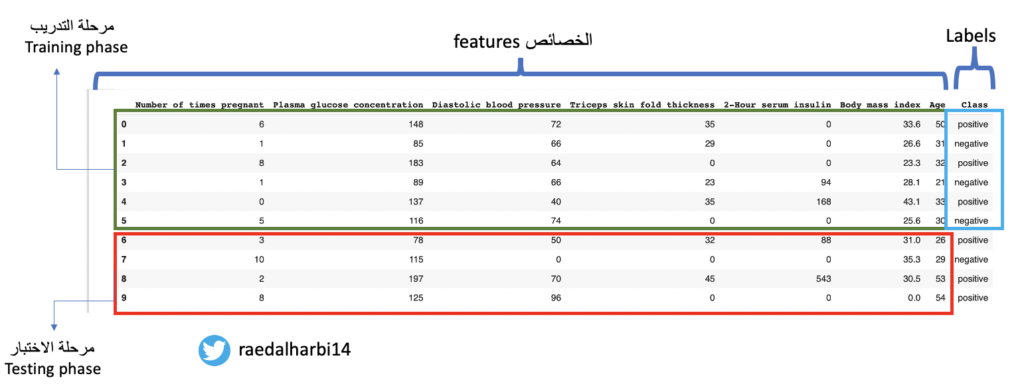
صورة رقم ١ : البيانات
الان طريقة بناء المودل model تتم على مرحلتين:
مرحلة التدريب training phase: في هذه المرحلة احنا نعطي المودل model الخصائص بالاضافة الى labels مثل ما نرى في الصورة رقم ١ حيث مرحلة التدريب تحتوي المربعين باللون الاخضر والارزق الفاتح. لكن لماذا مدخلات المودل تكون الخصائص بالاضافة الى labels؟ لماذا لا نكتفي بالخصائص فقط بما انه احنا نريد توقع ما اذا كانت المريضة مصاب بداء السكري والذي هو labels؟ السبب بسيط وهو انه احنا نتعامل مع ألة بالتالي في مرحلة التدريب احنا حنخبر المودل انه اذا شفت الخصائص التي ذكرت فاعرف انه المريضة مصابة بداء السكري لان احنا اخبرناه بذلك.
مرحلة الاختبار testing phase: هنا خلاص المودل المفروض تدرب كفاية. فاحنا في هذه المرحلة نعطي المودل فقط الخصائص والتي هيا تشخيص حالة المريضة ومن ثم الان دور المودل ان يقوم بتوقع ما اذا كانت المريضة مصابة بالسكري او لا والتي هيا labels لان المفروض تعلم يفرق بين المريضة المصابة والغير مصابة في مرحلة التدريب.
ملاحضة: كيف نتأكد من توقعنا انه صحيح؟ حنرجع لل labels في البيانات ونتاكد هل هو فعلا توقع المودل او لا. لان labels موجودة عندنا من الاساس بس ما اعطيناها المودل لان وظيفته يتوقع لنا في مرحلة الاختبار.
الان بعد المقدمة الطويلة ^ــ^ تعال نبدأ نشوف الأكواد
التعامل مع البيانات
في اول سطر استدعينا مكتبة panda وهي مكتبة مختصة للتعامل مع البيانات وتحليلها. ولو تلاحظ في اول سطر كتبنا as pd وهذا يعني باختصار انه كل ما جينا نتعامل مع المكتبة او الدوال الموجودة فيه حنستخدم الاختصار pd. في السطر الثاني احنا جلسنا نقرا البيانات واسندناها للمتغير الي سميناه data. وبعد ذلك طبعنا اول خمسة صفوف من البيانات مثل ما نشوف. في حال تريد تطبق المشروع بنفسك غير الرابط لمكان البيانات. في مثالنا هذا جبتها من قوقل درايف الخاص في.
ملاحضة: لو ظهر لك خطأ انه المكتبة غير موجودة لاي سبب من الاسباب، فاستخدم الامر التالي لتثبيت المكتبة:
مثل ما شفنا البيانات تحتوي كل الخصائص وال labels مع بعض. فاحنا نبغى البيانات التي تحتوي على الخصائص في متغير لحالها وحنسميه x وال labels في متغير ثاني لوحدها ايضا وحنسميه y_string . نشوف الكود التالي:
طبعا بما انه في البداية احنا استدعينا البيانات باستخدام المكتبة panda فاحنا نقدر نستخدم الدوال داخلها. في السطر الاول data.iloc تسمح لي اسوي slicing للبيانات مثل ما شفنا في مقالة ال slicing. طيب وبعد ذلك حددنا كل الخصائص بستثناء اخر عامود لان يحتوي labels واحنا نبغى نفصلهم.
السطر الثاني نفس الكلام نبغى عامود الذي يحتوي ال labels فقط وهذا هو العامود الاخير. وبعد ذلك حولناها الى list. لماذا؟ حنشوف الان. ملاحضة: طبعت نوعهم لنتاكد ونعرف احنا نتعامل مع ايش بالضبط
لماذا حولناها الى list؟
لان مثل ما تلاحظ عندنا في عامود ال labels. يوجد مصاب positive وغير مصاب negative. ونوعهم string فاحنا نبغى نحولهم لارقام حتى نتعامل معاهم. والحل؟ الحل بسيط نحول positive الى 1 و negative الى 0. يعني لو شفت 1 معناه المريضة معاه سكر ولو شفت صفر معناه المريضة غير مصابة بالسكر. نشوف الكود:
أول سطر استدعينا مكتبة numpy وهيا مكتبة تسمح لنا نتعامل مع array والمصفوفات بكل سهولة. بعد ذلك في السطر الثاني انشانا المتغير y_int من نوع list حتى نسند له كل الlabels الجديدة والتي هيا 1 او 0. بعد ذلك في السطر الثاني قلنا له امشي على كل البيانات الموجودة في المتغير y_string والذي نعرف سابقا انه يحتوي ال labels. ومن سطر ٤ الى ٧. قلنا له اذا قابلك positive معناه حط لي رقم 1 والعكس. واخر سطر ٨ حولنا ال list الى numpy array.
ممكن تسأل انت من بداية المقالات وانت تتكلم عن tensor في Pytorch والحين جالس تشرح numpy array وتستخدمها؟
احنا الحين نتعامل مع البيانات في البداية واستخراج البيانات والتعامل معاهااسهل كثير في بعض المكتبات من اخرى وله ادواته الخاصة لكن تأكد حنشتغل على tensor ونحول لها بمجرد ما نبني المودل لكن احنا الان نجهز البيانات وهذا ما حتشوفه في الحياة العملية لان ما في بيانات تجيك جاهزة. نكمل؟
الان حنسوي cross validation وتقدر تشوف هذا الفديو
من هنا
الموضوع جديد عليك. لكن الفكرة العامة انه نبغى نقسم بياناتنا الى بيانات التدريب لاستخدامها في مرحلة التدريب وبيانات الاختبار لاستخدامها في مرحلة الاختبار. لماذا التقسيم؟ لان ما ينفع ندرب المودل على كل البيانات بعدين كيف نختبر المودل؟ لان لازم نختبره على بيانات ما رأها من قبل. تقسيمنا حيكون كالاتي ٢٠ بالمية من البيانات حتكون للاختبار والباقي للتدريب. وعندنا مجموع البيانات ٧٦٨ فتقريبا ٢٠ بالمية منها حتكون ١٥٤. نشوف الكود:
استخدمنا الدالة train_test_split من مكتبة sklearn. وبعد ذلك استدعينا الدالة ومررنا له x والتي تحتوي كامل البيانات وهي الخصائص و y والتي تحتوي كامل labels والتي هيا صفر او واحد. الدالة تقبل numpy array ولهذا مثل ما شفنا قبل ليش حولت y من list الى numpy array. طبعا test_size اعطيناها ٢٠ بالمية التي شرحتها وايضا قلنا له shuffle = false والذي يعني لا تلخبط البيانات وتاخذ بشكل عشوائي. وبعد كذا نشوف المخرجات عندي ٤ شغلات: X_train,X_test,y_train,y_test . X_train و X_test يحتويان الخصائص فقط لكن بعضها حنستخدمها للتدريب والبعض الاخر للاختبار. نفس الكلام y_train و y_test تحتوي ال labels فقط لكن بعضها للتدريب والبعض الاخر للاختبار. نتاكد ونطبع؟ نشوف الكود :
صورة رقم ٢ : بيانات التدريب والاختبار
مثل ما نشوف في الصورة اعلاه. للتدريب حنستخدم X_trainوy_train، طبعا x_train تحتوي على الخصائص وبالنسبة ل y_train تحتوي على ال labels. . مثل ما ذكرت في البداية حنقول للمودل هاذي الخصائص للمريضة اذا توفرت فيها معناه مريضة والتي هيا labels والتي هيا هنا y_train. نلاحظ حجم X_train ٦١٤ على ٧. ٦١٤ هيا عدد الصفوف لكن لماذا ٧ اعمدة؟ لان هيا عدد الخصائص. بالنسبة y_train هيا ٦١٤ ولكن على واحد والذي هو عامود ال label فقط لكن ما يكتب الواحد هنا. نفس الكلام ينطبق فعليا على X_test و y_test.
بناء Multilayer Perceptron Model
أول شي حنسويه قبل نبني المودل ان نحول بيانات التدريب والاختبار الى tensor حتى نتعامل معاها باستخدام مكتبات Pytorch. نشوف الكود التالي:
نلاحظ حولنا البيانات الى tensor وبعد ذلك طبعت احجامهم وما في شي تغير نفس الاحجام. واخيرا طبعت النوع حتى نتاكد انها تحولت الى tensor. الان خلينا نشوف الكود للمودل الذي حنبنيه:
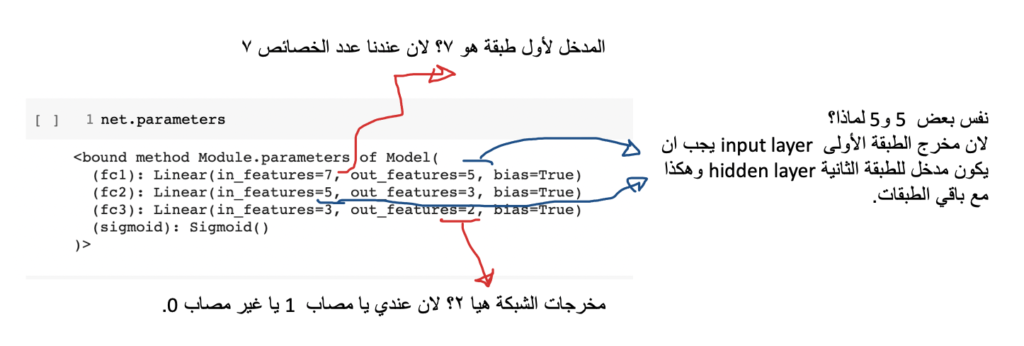
Multilayer Perceptron Model: صورة رقم ٣
تعال نفصل في الصورة وحدة وحدة. أول شي عند تطبيق او بناء اي مودل model باستخدام pytorch. الجزء الذي كتبت عليه “تغير حسب مودلك” هو فعليا ما تحتاج ان تغيره فلا تتوهك الاكواد الاخرى في حال كنت تبغى تبني مودلك الخاص. طيب الان مثل ما ذكرت في مقالة multilayer perceptron model. احنا نتعامل مع linear layer اي كل الوحدات العصبية متصلة مع بعضها البعض. في مثالنا اعلاه. من السطر ٦ الى السطر ٨ احنا مجرد انه عرفنا انه عندي ٣ طبقات fc1 و fc2و fc3. طبعا fc1 تمثل طبقات المدخلات بالنسبة لنا والتي هيا الخصائص x. وطبقة fc2 تمثل الطبقة المخفية الاولى واخيرا fc3 والتي تمثل طبقة المخرجات. ملاحظة في الصورة في طبقة مخفية ثانية hidden layer 2. اعتبر ما عندنا هذه الطبقة لان ما حنحتاجها. نكمل؟ سطر رقم ٩ مجرد عرفنا activation function من نوع sigmoid.
الان من سطر ١٢ الى سطر ١٦ هذا هو ال Forward pass الذي ذكرته واتكلمت عنه بالتفصيل في مقالة multilayer perceptron . تعال نستدعي المودل وبعدها نتكلم عن المدخلات والمخرجات واشكالها. نشوف الكود التالي:
اول شي نشوف تعريف المدخلات والمخرجات لطبقة linear layer من موقع pytorch الرسمي.
نلاحظ انه تستقبل خصائص وهيا in_features وتخرج لنا مخرجات وهيا out_features. تمام؟ تعال نطبع مدخلات ومخرجات شكبتنا ونحاول نفهم الكود:
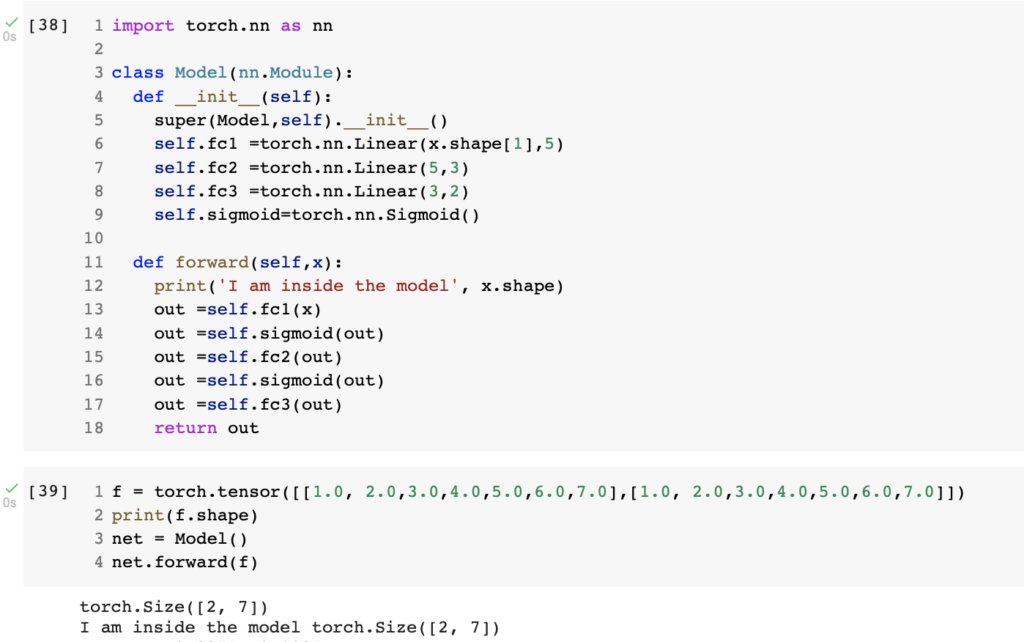
اول شي لطباعة معلومات الشبكة الخاصة فينا. نستخدم الامر net.parameters. الان مثل ما نشوف في رسمة الشبكة في صورة رقم ٣. عندنا طبقة المدخلات أول شي والمدخلات نعرف انها عندي عبارة عن خصائص والتي هيا تشخيص المريضة وعددها ٧ خصائص. بعدين المخرج لطبقة fc1 هو 5؟ هنا انت مخير كم عدد dimension للخصائص فتقدر تحط ارقام مختلفة وتجرب. نفس الكلام للطبقة المخفية. نجي للاخير ونشوف عندي مخرج fc3 هو ٢ بناء على ال labels.
ملاحضة:حشرح في مقالة لاحقا اكثر عن ايش ممكن الارقام الي نختارها لكن اي رقم يعكس لك دقة عالية للمودل اختاره.
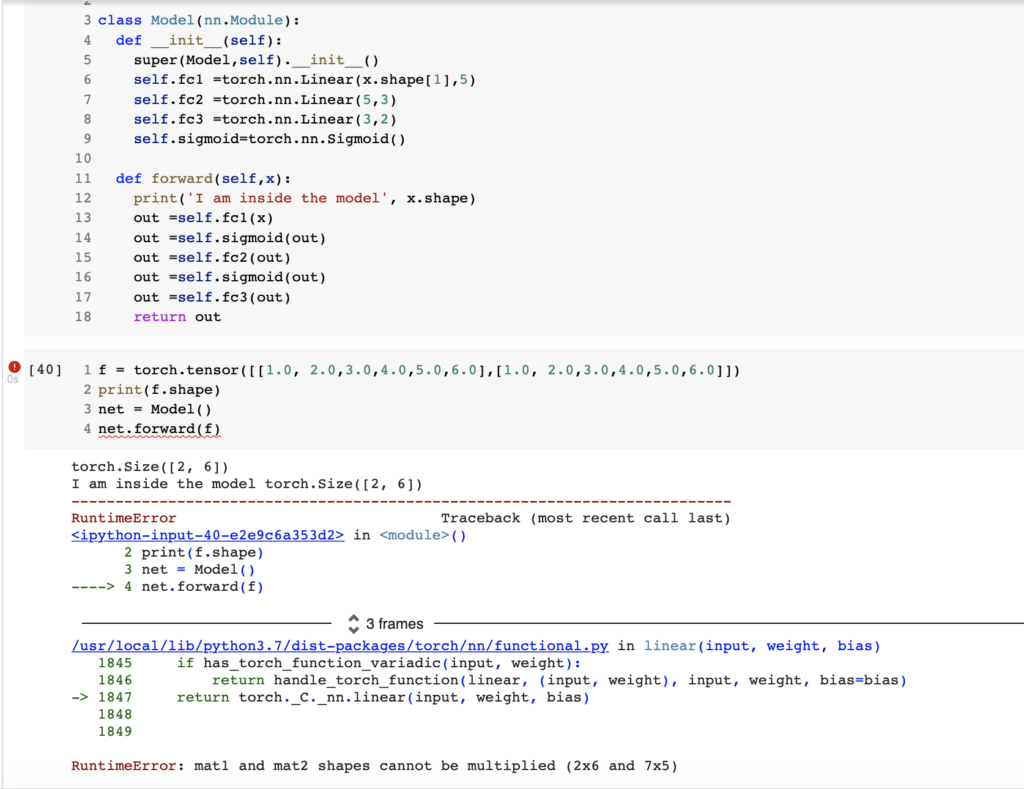
نشوف السطر رقم ٦ في صورة رقم ٢ ونلاحظ اني كتبت x.shape[1] عند تعريف الطبقة والتي هيا ٧ لان صفر تعني عدد الصفوف وواحد تعني عدد الاعمدة. ولو استبدلناه ب٧ برضه حيكون صحيح. فاحنا في سطر ٦ حددنا النوع الذي متوقعين ان يجي للطبقة. الان نشوف سطر ١٢ ونلاحظ انه المدخل للطبقة الاولى وهي طبقة المدخلات هو x. ولاحظ ايضا ان x في سطر ١١ حنرسلها. يعني اي شي حنرسله للمودل حيجي هنا للطبقة fc1 ومن خلال تعريفنا للطبقة نعرف انه لازم تجيني ٧ خصائص او المودل حيعطيني خطا. تبغى تتأكد؟
التحقق من مدخلات ومخرجات المودل
تعال نجيب قيمة عشوائية من عندنا ويكون حجمها (2,7) والمفروض المودل يقبلها لان عرفنا حيجيك ٧ خصائص. نشوف الكود:
نلاحظ في السطر الاول انشانا tensor بقيم من عندنا وبعد ذلك في سطر ٣ استدعينا المودل وبعد ذلك في سطر ٤ سوينا عملية Forward pass لقيمة من عندنا مو للخصائص الفعلية في البيانات حتى نتاكد وبعد ذلك في سطر ١٢ طبعنا حتى نشوف. وتلاحظ انه فعلا المودل قبل البيانات وبدون اي مشاكل. ماذا لو غيرنا وارسلنا له حجم (2,6) هل يقبل؟ نشوف
نلاحظ انه ما قبل لان حجم البيانات لا يتناسب مع البيانات المطلوبة. هذه احدى الطرق كيف تتاكد من حجم البيانات وهل يتناسب قبل ما تبدا تدرب المودل الخاص فيك. ولاحظ فين طبعت الحجم في سطر ١٢ بعد ما ارسلنا المدخلات حتى اتاكد من المدخلات.
مرحلة التدريب والاختبار
انا ذكرت بالتفصيل في هذه المقالة وقلت ان عند تدريب model نحتاج ٣ مراحل وذكرت تفاصيل كل مرحلة. فاذا كنت مو فاهم ايش يتم في كل مرحلة وليه نحتاجهم انصحك ترجع للمقالة. المراحل التي نحتاجها عند تدريب اي مودل سوا MLP او CNN هيا كالاتي:
Forward pass
Calculate error or loss
Backward pass
نشوف الصورة التالية ونكمل:
مثل مو ظاهر في الصورة حنبدا وننفذ كل مرحلة بالترتيب. لكن اول شي خلينا نختار loss function التي سنستخدم في المرحلة الثانية. وايضا ما نوع ال optimizer الذي سنستخدمه لتحديث الاوزان كل مرة في المرحلة الثالثة. بالاضافة اكيد الى استدعاء المودل الذي بنيناه. تعال نشوف الكود:
optimzerو loss function صورة رقم ٤ : تهيئة المودل و
اخترت CrossEntropyLoss() حتى تحسب لنا نسبة الخطأ بين التوقع للمودل الخاص فينا وهو predicted labelsوبين ال labels الحقيقية الموجودة في البيانات. ايضا استخدمنا Adam والذي سيتولى مهمة تحديث الاوزان كل مرة. ايضا تلاحظ انه حددنا learning rate واعطيناه قيمة 0.01.
ماهو هدفنا من مرحلة التدريب من الناحية النظرية؟
نوصل للاوزان المناسبة التي تقلل لنا نسبة الخطأ بين توقع المودل وبين قيمة الlabel الحقيقية في البيانات. في المرحلة الاولى: نحسب dot prouct والناتج حيكون توقع وهي الاوزان. المرحلة الثانية: حنحسب نسبة الخطا باستخدام CrossEntropyLoss() واكيد حيكون التوقع في اول مرة خطا لان الاوزان في البداية تكون صفر او عشوائية وبالتالي نسبة الخطا حتكون عالية loss error. بالتالي نروح للخطوة الثالثة ونحدث الاوزان باستخدام gradient decent واستخدمنا هنا Adam. وضحت الصورة؟ ارجع للمقالة التي اشرت لها اذا تحتاج توضيح اكثر. نشوف الكود:
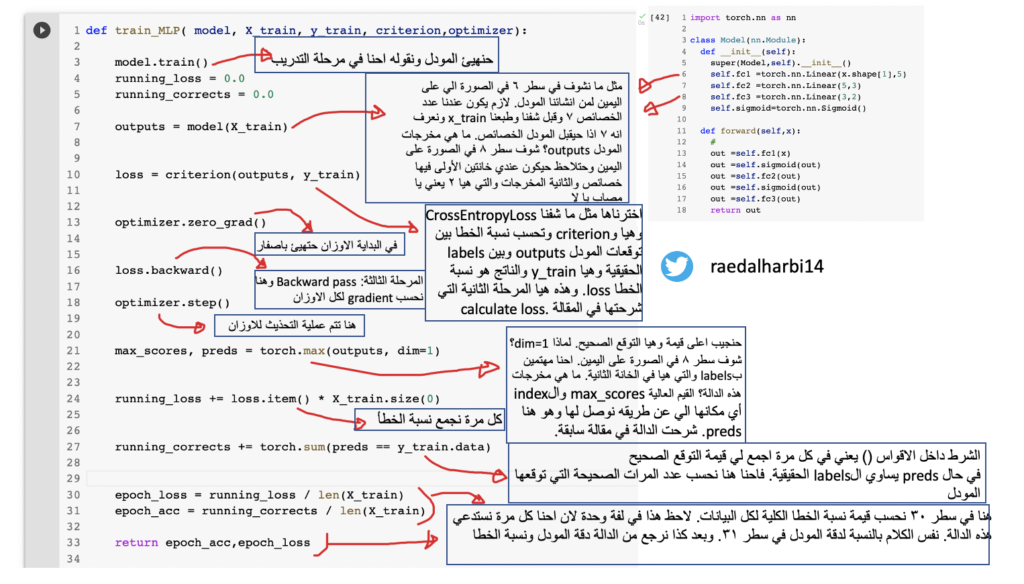
صورة رقم ٥: كود التدريب
قبل ما نشغل الكود حنفهمه اول شي. في الصورة وضحت كل شي ولكن ابغى انوه اني الى الان ما وريتك ما هي محتويات دالة التدريب train_MLP التي استدعيتها في سطر ١١ وايضا دالة الاختبار vaildate_MLP في سطر ١٧. المفهوم العام في الصورة اعلاه. احنا حنجلس نلف ٦١٤ مرة وفي كل مرة حنرسل لدالة التدريب المودل net الذي هينئنها قبل بالاضافة الى loss_function وايضا optimizer مثل ما نشوف في صورة رقم ٤. بالاضافة الى ذلك ارسلنا بيانات التدريب X_train وال labels المقابل لها y_train مثل ما شفنا في صورة رقم ٣. وبعدها وظيفة الدالة ترجع لي دقة المودل بالاضافة الى نسبة الخطا. طعبا نسبة الخطا كل ما كانت قليلة كانت شي ممتاز والدقة كل ما كانت عالية تدل على انه المودل يتدرب بشكل صحيح. نفس الكلام ينطبق على دالة الاختبار في سطر ١٧ ولكن مع بيانات الاختبار. وايضا لاحظ انه ما ارسلنا optimizer في دالة الخطا. لماذا؟ لان خلاص احنا دربنا المودل فما عاد نحتاج نحدث الاوزان. نشوف الان دالة بيانات التدريب.
واضحة الصورة؟ تعال نشوف دالة الاختبار وهيا بالضبط نفس دالة التدريب لكن الفرق انه ما حنحتاج نحدث وبالتالي ما في optimizer بالاضافة الى انه بدال model.train(). وضعنا model.eval() لان نهيئ المودل ونخبره انه احنا في مرحلة الاختبار. نشوف الكود
الحين خلينا نرجع للكود في صورة رقم ٥ ونشغله ونشوف جزء من عملية الطباعة
نلاحظ انه جالس يدرب ويطبع لنا نسبة الخطا ودقة المودل. ودقة المودل الخاص فينا تقريبا ٧٨٪. تعال نشوف ما فائدة سطر ١٢ و١٣ في صورة رقم ٥. نفس الكلام في سطر ١٨ و١٩. للكل في مرحلة التدريب والاختبار. في الصور شرحت وقلت انه انشائنا كم لستة وجلسنا نحفظ النسب لدقة المودل لكل epoch بالاضافة الى نسبة الخطا loss لدالة التدريب والاختبار. ليه؟ نشوف الصورة التالية
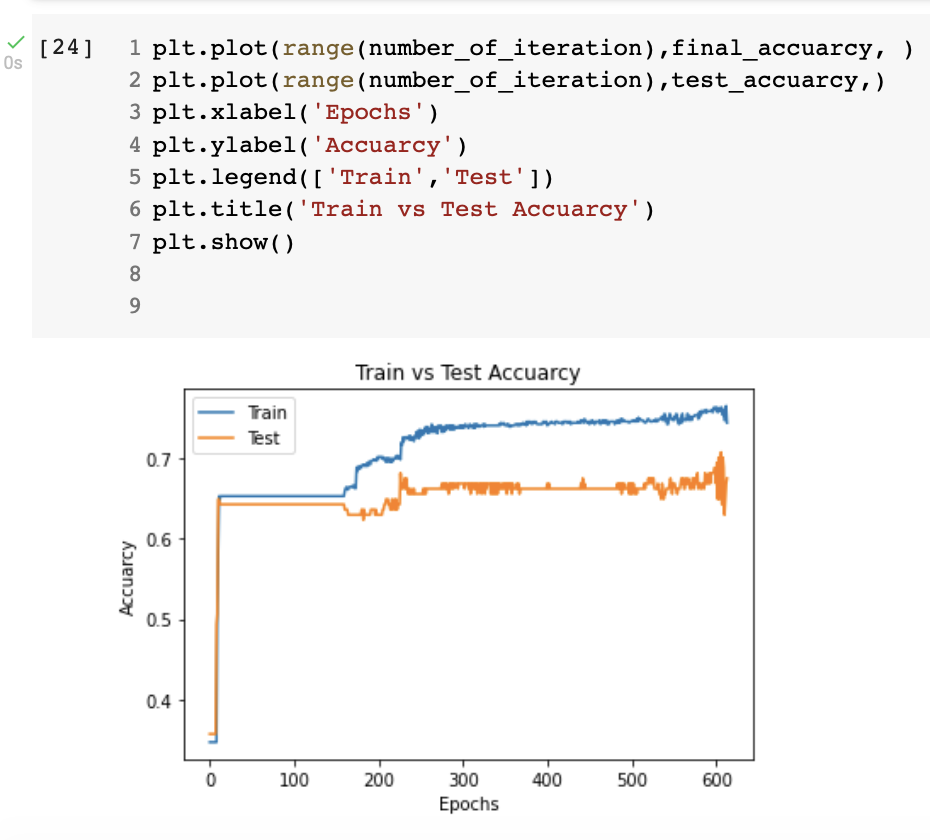
اول شي استخدمت مكتبة matplotlib والتي توفر لنا عرض انواع مختلفة للصور وال graph لبياناتنا. في السطر الاول استدعيت المكتبة. الدالة plt.plot تاخذ خانتين الاولى هيا x وفي مثالنا وضعنا عدد اللفات من ١ الى ٦١٤. والخانة الثانية التي هيا y ووضعنا final_losses التي تحتوي على جميع نسب الخطأ في مرحلة التدريب ونفس الكلام في سطر ٣ ولكن لجميع نسب الخطا في دالة الاختبار وهي test_losses. سطر ٤ و٥ نحن نسمي الاعمدة على x-axis و y-axis. سطر ٦ طبعنا legend الي نشوفه في اعلا الصورة على اليمين. سطر ٧ طبعنا عنوان الصورة. وفي الاخير عرضنا الصورة.
ماذا تعني الصورة؟
تعني ان المودل الذي انشائنا يتدرب بشكل صحيح. فنلاحظ نسبة الخطا في البداية عند اول ٥٠ لفة كانت عالية ومع مرور اللفات بدات نسبة الخطا تقل. ايضا نسبة الخطا لمرحلة الاختبار تعتبر مقبولة. نشوف الان ال plot اخر لكن بالنسبة لدقة المودل.
هنا نفس الكلام لكن جالسين نشوف نسب دقة المودل خلاص مرحلة التدريب والاختبار في جميع ال٦٠٠ لفة. ونلاحظ في البداية في اول ٤ لفات، دقة المودل كانت حوالي ٣٠ بالمية في مرحلة التدريب والاختبار ولكن مع زيادة اللفات زادت دقة المودل. وصلنا اعلى دقة في مرحلة التدريب الى حوالي ٧٨٪ وتقريبا ٦٨٪ بالنسبة لمرحلة الاختبار.
هذا الكود كامل للتحميل من هنا وشرح كيفية اعادة تشغيل الكود من هنا.
ملاحضات مهمة من المشروع
هدفي ليس الوصول لدقة عالية في هذا المشروع بس هدفي تفهم كيف كل شي ماشي وتستوعب الموضوع بشكل كامل. فيه شغلات كثيرة نحسن فيها المودل ما تطرقت لها لان كنت ابغى اوصل لك المفهوم الاساسي وفكرة ال multilayer preceptron. في المشروع القادم حشرح مشروع اكبر وحشرح تقنيات اكثر بعد ما نخلص من الجانب النظري المتبقي
انصحك تطبق المشروع بنفسك وتحاول تغير وتلعب في عدد layers والمدخلات والمخرجات لتستوعب اكثر المفهوم
اذا خرجت من هذه المقالة وفهمت الموضوع فكل شي مستقبلي حيقابلك حيكون اسهل بكثير. عشان كذا، اقرا المقالة مرة واثنين وثلاثة الين تستوعب.
ان اصبت فمن الله وان اخطات فمن نفسي ..
لا تنسى مشاركة المقالة اذا أعجبتك ..
اخوكم رائد الحربي
ولاي ملاحضات او استفسارات يرجى مراسلتي على تويتر @raedalharbi14 أو كتابة التعليق هنا














شكراً على مجهود حضرتك
هل ممكن تترك ملف جوجل كولاب هنا؟
يا أخي ، أبغى الملف الخاص بالكود.
راسلتك بتويتر وما بترد وعلقت وما في رد.
اتفضل اخي هذا الرابط فيه جميع الدروس العملية
https://colab.research.google.com/drive/1Wj7N5J-_w_JHc2yisIxczmfIe9mgksBO?usp=sharing
الله يعطيك العافية , شرح ممتاز و مبسط , شكرا