حاليا تعتبر تطبيقات التعلم العميق من أنجح تطبيقات الذكاء الاصطناعي. في هذه المقالة ساشرح تطبيق اطلق مؤخرا من OpenAI وهي شركة غير بحثية مختصة بتطبيقات الذكاء الاصطناعي.
ما هي فكرة تطبيق DALL.E 2 (دالي-٢)؟
قدرة النظام على انشاء صور بناء على وصف يعطى للشبكة العصبية (text to image)
قدرة النظام على انشاء رسومات ابداعية عن طريق فقط إعطاء صور للشبكة العصبية
تعال ناخذ مثال بسيط على النقطة الاولى. لو اعطينا النموذج المصمم proposed model وصف “كلب يرتدي قبعة سوداء”
حتكون النتيجة كالتالي:
والان حناخذ مثال على النقطة الثانية. افرض انه اعطينا النموذج المقترح proposed model صورة ثقب بركاني؟ والنتيجة حتكون الصورة نفسها بشكل ابداعي:
ما هي تفاصيل النموذج المقترح؟
النظام المقترح يتكون من نقتطين:
CLIP (Contrastive Language–Image Pre-training)
diffusion model وهو هنا ال decoder
تعال نرى الخطوة الأولى من النموذج المقترح ونشرحها بالتفصيل:
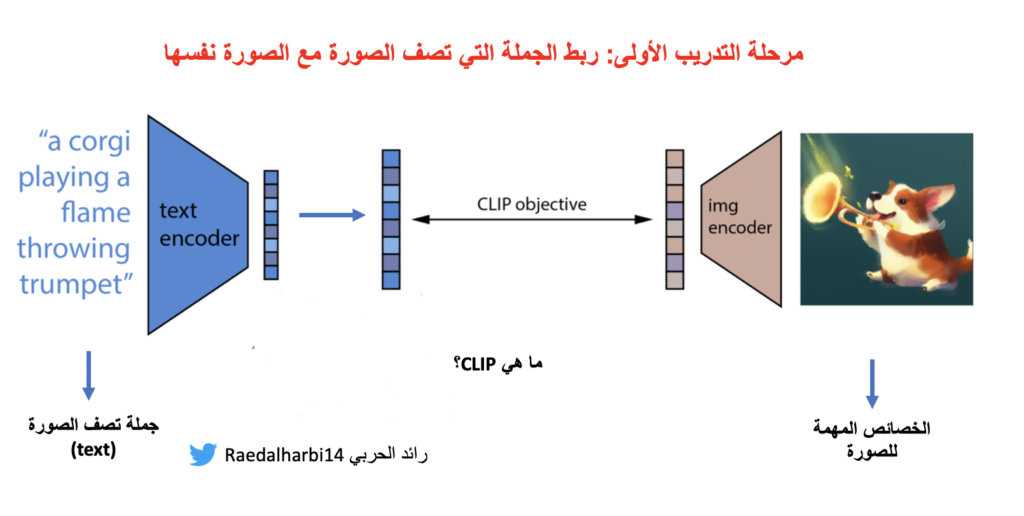
أول خطوة في بناء النموذج المقترح هيا ان نقوم بتدريب نموذج منفصل seperate model وفكرة هذا النموذج المنفصل ان يقوم النموذج ببناء وانتاج الخصائص المهمة التي تربط الصورة بالجملة. مثلا لو قلنا للنموذج “ارسم لي صورة كلب” اعزكم الله. سوف يقوم النموذج هذا بربط الخصائص المهمة الموجودة في صورة الكلب مثلا العيون والخطوط التي تكون صورة الكلب. بعد ذلك، يربط هذه الخصائص بكلمة كلب. كيف يقوم بهذه العملية بالتفصيل؟ التفاصيل بهذه العملية موجودة في ورقة علمية سابقة وهيا CLIP. ولكن الفكرة مثل ما ذكرت لك. طيب ممكن تقول على الاقل ابغى اعرف كيف يعرف انه هذه الجملة للصورة الفلانية؟ هذه بكل اختصار حتكون معطى. يعني تم بناء قاعدة بيانات كبيرة تحتوى ملاين الجمل وفي المقابل لها الصور الخاصة فيها.
ما هو مخرج النموذج الأول؟ خصائص الصور مع خصائص الجمل التي لها علاقة بالصورة. يعني كل كل صورة وعندها خصائصها التي تقابلها في الجملة.
تعال نرى الخطوة الثانية من النموذج المقترح ونشرحها بالتفصيل:
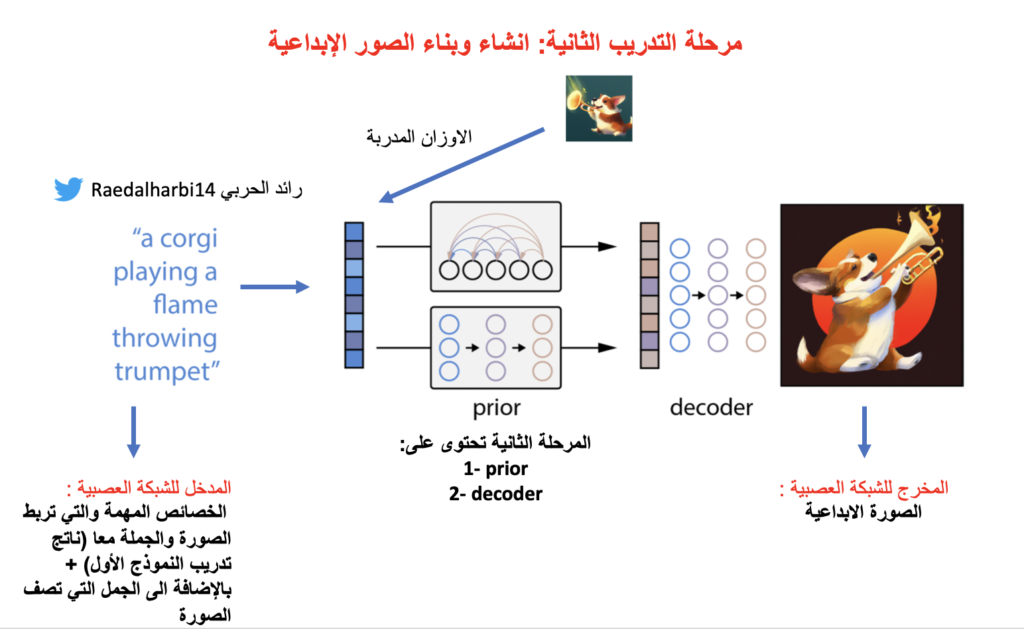
كما نلاحظ في الصورة اعلاه، الجزء الثاني من النموذج يتكون من
prior: وظيفته هو ان ينتج لنا خصائص الصورة بناء على الجملة وبناء على الاوزان التي ربطت الصورة بالجملة في مرحلة التدريب الاولى مثل ما نشوف من الورقة العلمية :
حيث z هيا الخصائص الخاصة بالصورة. حيث نبغى نجيب ناتج احتماليتها بناء على الجملة y
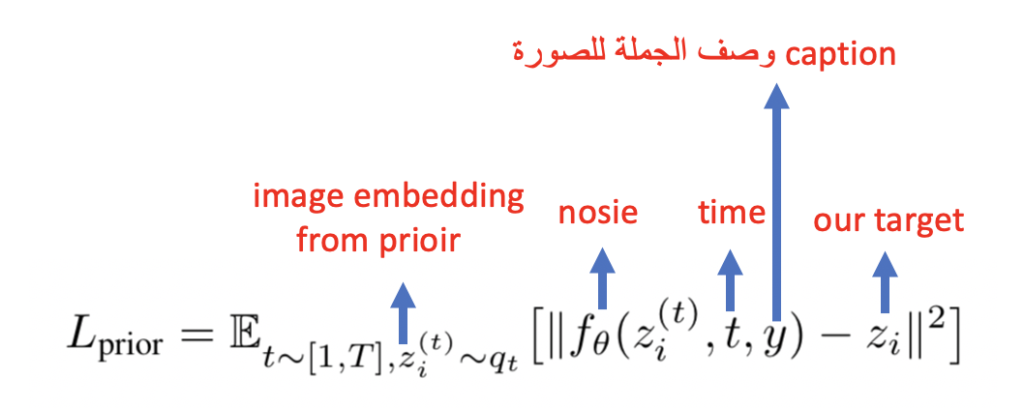
وحتكون عندنا دالة التدريب كالاتي:
لو تلاحظ كما وصفتها. وهيا انه بشكل مستمر نبدا نضيف nosie وبعدين نعكس العملية حتى نحصل على النتيجة.
decoder: وهنا تم استخدام Diffusion Model لكن بطريقة مختلفة عن الطريقة المعروفة. حعطي مقدمة بسيطة عن فكرة Diffusion Model. بعض النماذج مثل GAN, VAE عندها بعض العيوب وانه ما نستطيع نعممها generalized well بسبب طريقة عملها. وهنا جات فكرة Diffusion Model وهو انه ناخذ عينة من sampled from a real data distribution واعتبر انه عندي مجموعة صور واخذنا منها صورة وبعد ذلك نضيف لها ارقام عشوائية من Gaussian noise حتى تصبح الصورة غير واضحة ومن ثم نعكس العملية حتى نحصل على الصورة الحقيقة وهذا باستخدام الوقت يعني كل مرة تتم العملية عند ti وهذه الطريقة اثبتت فعاليتها لكن بما انه مو موضوعي الاساسي عنها فممكن اتكلم عنها بشكل مفصل لاحقا.
هنا ال Diffusion Model استخدم بطريقة مختلفة وهيا ان المدخل حيكون خصائص الصور image embeddings والتي كانت من مخرجات ال prior في النقطة الاولى.
بعض التجارب
تعال نشوف الصورة التالية والتي تظهر لنا قوة prior المقترح.
هنا اختبرو قوة prior عن طريق انهم اخذو الصورة الاساسية على اليمين وحولوها project الى CLIP latent space. وبعدين استخدمو PCA ليعطيهم اعلى نقاط مهمة ومثل ما نشوف في اخر صورة على اليسار. الصورة حافظت على الاشياء الاساسية من غير ما تقولنا ايش المدينة هذه بالضبط. ماذا يفيدنا هذا؟ هذا يدل على انه الخصائص المهمة للصورة تم تعلمها بالشكل الصحيح وبالتالي نقدر نستخدمها في تطبيقات اخرى من غير تاثير الاشياء الاخرى. طبعا احد استخدامات PCA انه يحول لي الخصائص الكثيرة الى خصائص قليلة وهذا الي طبقوه هنا بالضبط فنلاحظ انه اهم الخصائص كانت فعلا متعلقة بفحوى الصورة الاساسية.
خلينا نشوف صورة اخرى ونشرحها :
هنا يبغو يشوفون كيفية عمل ال decoder. فاول شي هنا طبقوه انهم اخذو الجملة وفي مثالنا هذا انه” لوحة زيتية لكلب من فصيلة كارجي يرتدي قبعة” بالاضافة الى خصائص الصورة وهيا CLIP image embedding والتي هيا مربوطة بالجملة المعطى مثل ما شفنا كيف قبل. والناتج الصورة التي في الاعلى.
بعض الاسئلة التي تحتاج الى اجابة
خلال قراتي الورقة العملية كنت ابحث اولا عن ما مدى تعقيد هذا النموذج وكم من الوقت يحتاج لتدريبه لكن للاسف لم اجد هذه المعلومة. واعتقد انه حتى يتم انتاج مثل هذه التطبيقات وتدريب نموذج ممثال نحتاج كمية هائلة من البيانات. لك ان تتخيل ان عدد الاوزان المستخدمة في الورقة هيا بالبلايين. فممكن تفكر في هذه الاسئلة عن التفكير في استخدام او بناء نماذج مماثلة
ان اصبت فمن الله وان اخطات فمن نفسي ..
لا تنسى مشاركة المقالة اذا أعجبتك ..
اخوكم رائد الحربي
ولاي ملاحضات او استفسارات يرجى مراسلتي على تويتر @raedalharbi14 أو كتابة التعليق هنا
تحليل ممتاز للورقة البحثية هذه.
لما قرأت انه نحتاج كم بيانات هائل لتدريب مثل هذا الموديل، صراحة انصدمت. اعتقد انه موجه للشركات مثلا في الاستخدام مش للأفراد؟ هل نقدر نستفاد كمؤسسات صغيره او شركات ناشئة من هذه التطبيقات بدون كم بيانات هائل؟




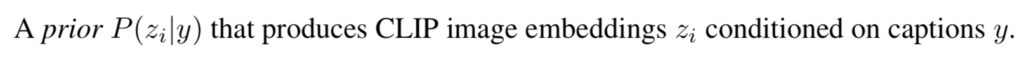
تحليل ممتاز للورقة البحثية هذه.
لما قرأت انه نحتاج كم بيانات هائل لتدريب مثل هذا الموديل، صراحة انصدمت. اعتقد انه موجه للشركات مثلا في الاستخدام مش للأفراد؟ هل نقدر نستفاد كمؤسسات صغيره او شركات ناشئة من هذه التطبيقات بدون كم بيانات هائل؟